

Immagini Getty
Nel mondo dell'intelligenza artificiale, quelli che potrebbero essere chiamati “piccoli modelli linguistici” sono diventati sempre più popolari di recente perché possono essere eseguiti su un dispositivo locale invece di richiedere laptop di livello knowledge middle nel cloud. Mercoledì, Apple introdotto una serie di minuscoli modelli linguistici AI disponibili all'origine chiamati OpenELM che sono sufficientemente piccoli da poter essere eseguiti direttamente su uno smartphone. Per ora sono per lo più modelli di ricerca proof-of-concept, ma potrebbero costituire la base delle future offerte di intelligenza artificiale su dispositivo di Apple.
I nuovi modelli di intelligenza artificiale di Apple, collettivamente denominati OpenELM per “Modelli linguistici efficienti open supply”, sono attualmente disponibili su Volto che abbraccia sotto un Licenza del codice campione Apple. Poiché ci sono alcune restrizioni nella licenza, potrebbe non adattarsi a definizione comunemente accettata di “open supply”, ma il codice sorgente per OpenELM è disponibile.
Martedì abbiamo coperto I modelli Phi-3 di Microsoft, che mirano a ottenere qualcosa di simile: un livello utile di comprensione del linguaggio e prestazioni di elaborazione in piccoli modelli di intelligenza artificiale che possono essere eseguiti localmente. Phi-3-mini presenta 3,8 miliardi di parametri, ma alcuni dei modelli OpenELM di Apple sono molto più piccoli, variando da 270 milioni a 3 miliardi di parametri in otto modelli distinti.
In confronto, il modello più grande mai lanciato nel Il lama di Meta 3 La famiglia embody 70 miliardi di parametri (con una versione da 400 miliardi in arrivo) e GPT-3 di OpenAI del 2020 viene fornito con 175 miliardi di parametri. Il conteggio dei parametri serve come misura approssimativa della capacità e della complessità del modello di intelligenza artificiale, ma la ricerca recente si è concentrata sulla creazione di modelli linguistici di intelligenza artificiale più piccoli tanto capaci quanto lo erano quelli più grandi qualche anno fa.
Gli otto modelli OpenELM sono disponibili in due versioni: quattro come “preaddestrati” (sostanzialmente una versione grezza, successiva del token del modello) e quattro come ottimizzati per le istruzioni (ottimizzati per seguire le istruzioni, che è più ideale per lo sviluppo di assistenti AI e chatbot):
OpenELM presenta una finestra di contesto massima di 2048 token. I modelli sono stati addestrati sui set di dati disponibili al pubblico Internet raffinatouna versione di MUCCHIO con le duplicazioni rimosse, un sottoinsieme di Pigiama rossoe un sottoinsieme di Dolma v1.6, che secondo Apple ammonta a circa 1,8 trilioni di token di dati. I token sono rappresentazioni frammentate dei dati utilizzati dai modelli linguistici dell'intelligenza artificiale per l'elaborazione.
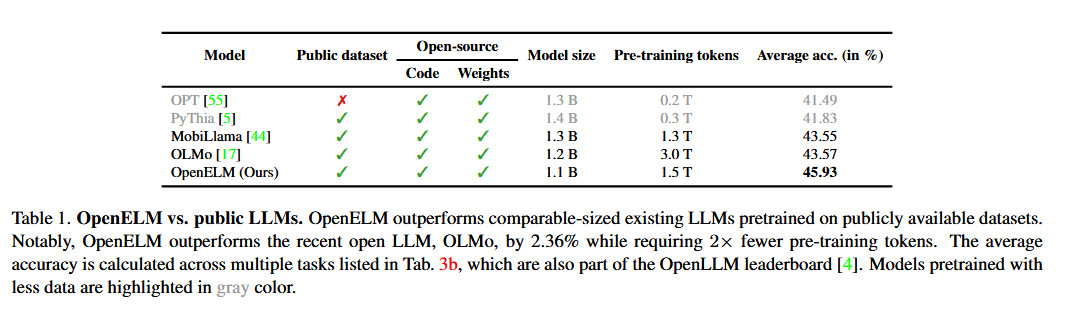
Apple afferma che il suo approccio con OpenELM embody una “strategia di ridimensionamento a livello di livello” che, secondo quanto riferito, alloca i parametri in modo più efficiente su ogni livello, risparmiando non solo risorse computazionali ma anche migliorando le prestazioni del modello mentre viene addestrato su un minor numero di token. Secondo il comunicato di Apple carta biancaquesta strategia ha consentito a OpenELM di ottenere un miglioramento della precisione del 2,36% rispetto a allen IA OLMo 1B (un altro piccolo modello linguistico) richiedendo la metà dei token di pre-formazione.
Mela
Apple ha anche rilasciato il codice per CoreNet, una libreria utilizzata per addestrare OpenELM, e includeva anche ricette di addestramento riproducibili che consentono di replicare i pesi (file di rete neurale), cosa finora insolita per una grande azienda tecnologica. Come afferma Apple nel suo summary su OpenELM, la trasparenza è un obiettivo chiave per l'azienda: “La riproducibilità e la trasparenza dei modelli linguistici di grandi dimensioni sono cruciali per far avanzare la ricerca aperta, garantire l'affidabilità dei risultati e consentire indagini sui dati e sui bias dei modelli, come così come i rischi potenziali.”
Rilasciando il codice sorgente, i pesi dei modelli e i materiali di formazione, Apple afferma che mira a “potenziare e arricchire la comunità di ricerca aperta”. Tuttavia, avverte anche che, poiché i modelli sono stati addestrati su set di dati di provenienza pubblica, “esiste la possibilità che questi modelli producano risultati imprecisi, dannosi, distorti o discutibili in risposta alle richieste degli utenti”.
Sebbene Apple non abbia ancora integrato questa nuova ondata di funzionalità del modello linguistico AI nei suoi dispositivi shopper, il prossimo aggiornamento iOS 18 (previsto per essere rivelato a giugno al WWDC) si cube che includa nuove funzionalità di intelligenza artificiale che utilizzare l'elaborazione sul dispositivo per garantire la privateness dell'utente, anche se la società potrebbe potenzialmente assumere Google o OpenAI per gestire elaborazioni AI più complesse e esterne al dispositivo per dare a Siri una spinta attesa da tempo.









{kind=link}