
Multimodal giant language fashions (MLLMs) combine textual content and visible knowledge processing to boost how synthetic intelligence understands and interacts with the world. This space of analysis focuses on creating techniques that may comprehend and reply to a mixture of visible cues and linguistic info, mimicking human-like interactions extra intently.
The problem typically lies within the restricted capabilities of open-source fashions in comparison with their industrial counterparts. Open-source fashions incessantly exhibit deficiencies in processing complicated visible inputs and supporting numerous languages, which may prohibit their sensible functions and effectiveness in numerous situations.
Traditionally, most open-source MLLMs have been educated at mounted resolutions, primarily utilizing datasets restricted to the English language. This strategy considerably hinders their performance when encountering high-resolution photographs or content material in different languages, making it tough for these fashions to carry out properly in duties that require detailed visible understanding or multilingual capabilities.
The analysis from Shanghai AI Laboratory, SenseTime Analysis, Tsinghua College, Nanjing College, Fudan College, and The Chinese language College of Hong Kong introduces InternVL 1.5, an open-source MLLM designed to considerably improve the capabilities of open-source techniques in multimodal understanding. This mannequin incorporates three main enhancements to shut the efficiency hole between open-source and proprietary industrial fashions. The three principal elements are:
- Firstly, a robust imaginative and prescient encoder, InternViT-6B, has been optimized by way of a steady studying technique, enhancing its visible understanding capabilities.
- Secondly, a dynamic high-resolution strategy permits the mannequin to deal with photographs as much as 4K decision by dynamically adjusting picture tiles based mostly on the enter’s side ratio and determination.
- Lastly, a high-quality bilingual dataset has been meticulously assembled, protecting widespread scenes and doc photographs annotated with English and Chinese language question-answer pairs.
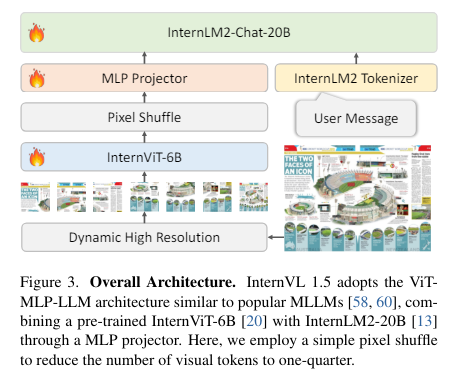
The three steps considerably increase the mannequin’s efficiency in OCR and Chinese language language-related duties. These enhancements allow InternVL 1.5 to compete robustly in numerous benchmarks and comparative research, showcasing its improved effectiveness in multimodal duties. InternVL 1.5 employs a segmented strategy to picture dealing with, permitting it to course of photographs in resolutions as much as 4K by dividing them into tiles starting from 448×448 pixels, adapting dynamically based mostly on the picture’s side ratio and determination. This technique improves picture comprehension and facilitates understanding of detailed scenes and paperwork. The mannequin’s enhanced linguistic capabilities stem from its coaching on a various dataset comprising each English and Chinese language, protecting a wide range of scenes and doc varieties, which boosts its efficiency in OCR and text-based duties throughout languages.

The mannequin’s efficiency is evidenced by its outcomes throughout a number of benchmarks, the place it excels notably in OCR-related datasets and bilingual scene understanding. InternVL 1.5 demonstrates state-of-the-art outcomes, exhibiting marked enhancements over earlier variations and surpassing some proprietary fashions in particular assessments. For instance, text-based visible query answering achieves an accuracy of 80.6%, and document-based query answering reaches a powerful 90.9%. In multimodal benchmarks that assess fashions on each visible and textual understanding, InternVL 1.5 constantly delivers aggressive outcomes, typically outperforming different open-source fashions and rivaling industrial fashions.

In conclusion, InternVL 1.5 addresses the numerous challenges that open-source multimodal giant language fashions face, notably in processing high-resolution photographs and supporting multilingual capabilities. This mannequin considerably narrows the efficiency hole with industrial counterparts by implementing a strong imaginative and prescient encoder, dynamic decision adaptation, and a complete bilingual dataset. The improved capabilities of InternVL 1.5 are demonstrated by way of its superior efficiency in OCR-related duties and bilingual scene understanding, establishing it as a formidable competitor in superior synthetic intelligence techniques.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Neglect to affix our 40k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is keen about making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.








{kind=link}