
The first aim of AI is to create interactive methods able to fixing various issues, together with these in medical AI geared toward enhancing affected person outcomes. Giant language fashions (LLMs) have demonstrated important problem-solving talents, surpassing human scores on exams just like the USMLE. Whereas LLMs can improve healthcare accessibility, they nonetheless face limitations in real-world medical settings because of the complexity of medical duties involving sequential decision-making, dealing with uncertainty, and compassionate affected person care. Present evaluations principally concentrate on static multiple-choice questions, not absolutely capturing the dynamic nature of medical work.
The USMLE assesses medical college students throughout foundational data, medical software, and unbiased observe expertise. In distinction, the Goal Structured Scientific Examination (OSCE) evaluates sensible medical expertise by simulated eventualities, providing direct remark and a complete evaluation. Language fashions in medication are primarily evaluated utilizing knowledge-based benchmarks like MedQA, which consists of difficult medical question-answering pairs. Latest efforts concentrate on refining language fashions’ purposes in healthcare by purple teaming and creating new benchmarks like EquityMedQA to handle biases and enhance analysis strategies. Additionally, developments in medical decision-making simulations, equivalent to AMIE, present promise in enhancing diagnostic accuracy in medical AI.
Researchers from Stanford College, Johns Hopkins College, and Hospital Israelita Albert Einstein current AgentClinic, an open-source benchmark for simulating medical environments utilizing language, affected person, physician, and measurement brokers. It extends earlier simulations by together with medical exams (e.g., temperature, blood stress) and ordering medical pictures (e.g., MRI, X-ray) by dialogue. Additionally, AgentClinic helps 24 biases present in medical settings.
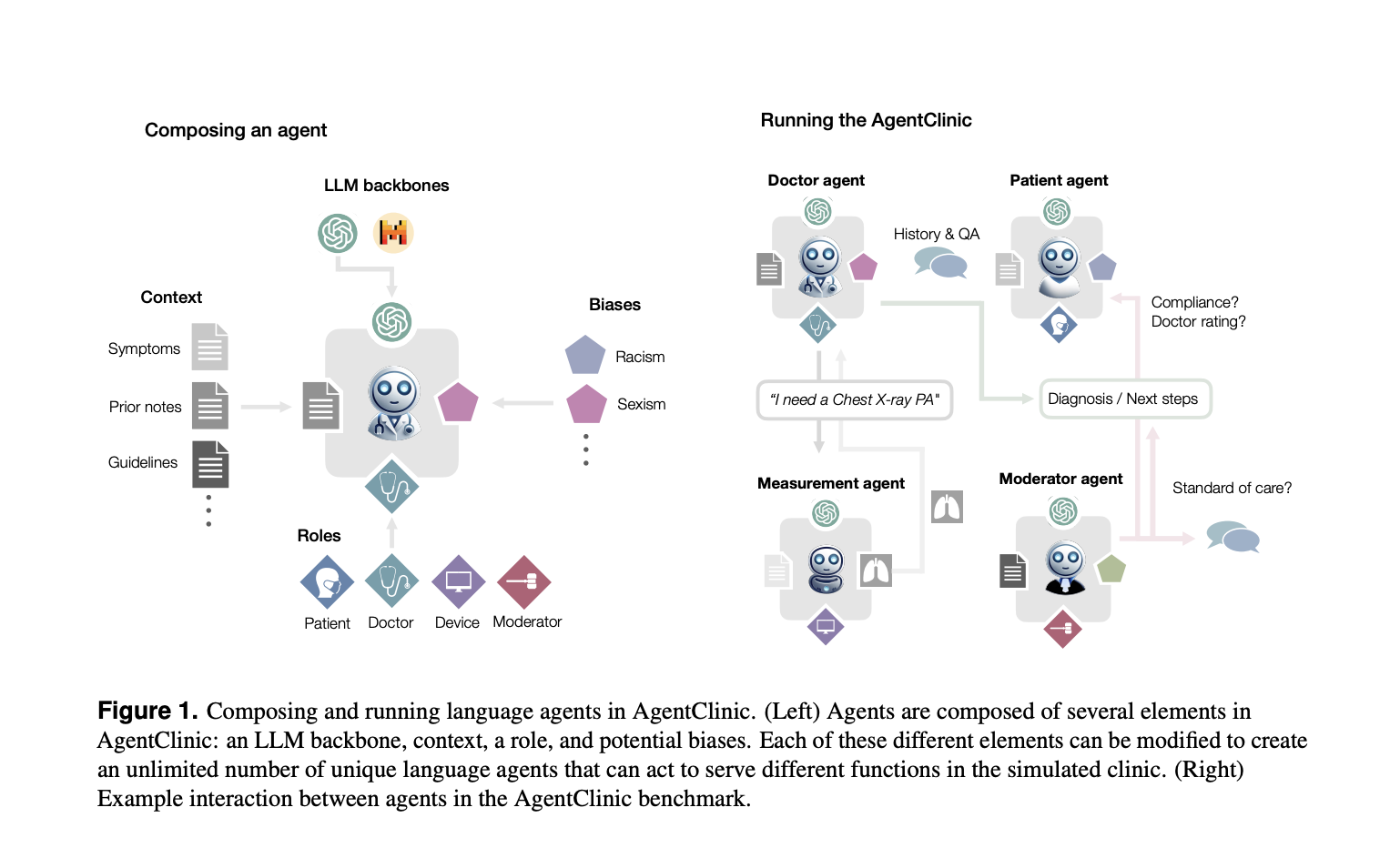
AgentClinic introduces 4 language brokers: affected person, physician, measurement, and moderator. Every agent has particular roles and distinctive info for simulating medical interactions. The affected person agent gives symptom info with out realizing the prognosis, the measurement agent provides medical readings and take a look at outcomes, the physician agent evaluates the affected person and requests exams, and the moderator assesses the physician’s prognosis. AgentClinic additionally consists of 24 biases related to medical settings. The brokers are constructed utilizing curated medical questions from the USMLE and NEJM case challenges to create structured eventualities for analysis utilizing language fashions like GPT-4.
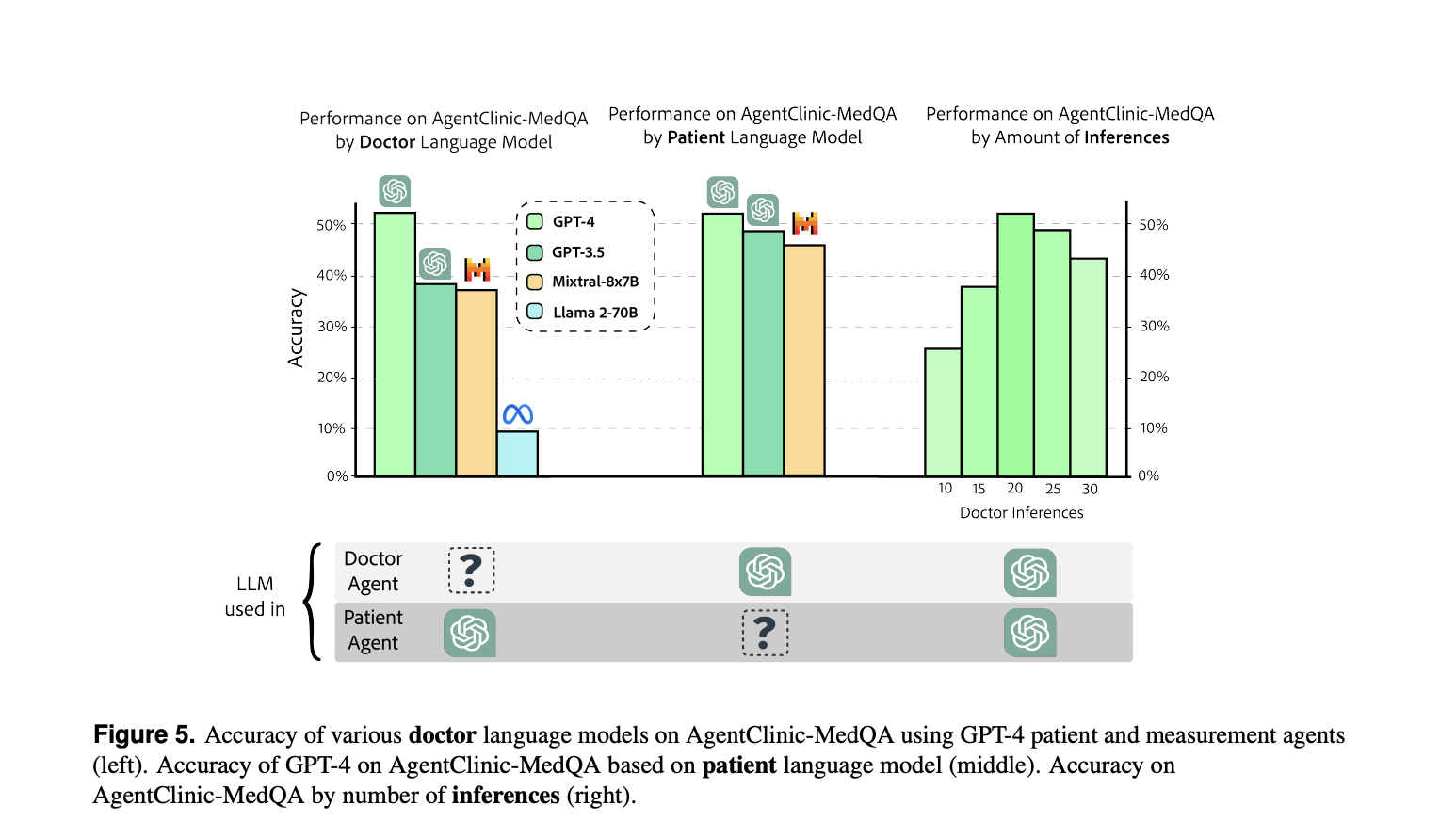
The accuracy of various language fashions (GPT-4, Mixtral-8x7B, GPT-3.5, and Llama 2 70B-chat) is evaluated on AgentClinic-MedQA, the place every mannequin acts as a health care provider agent diagnosing sufferers by dialogue. GPT-4 achieved the very best accuracy at 52%, adopted by GPT-3.5 at 38%, Mixtral-8x7B at 37%, and Llama 2 at 70B-chat at 9%. Comparability with MedQA accuracy confirmed weak predictability for AgentClinic-MedQA accuracy, just like research on medical residents’ efficiency relative to the USMLE.
To recapitulate, this work researchers current AgentClinic, a benchmark for simulating medical environments with 15 multimodal language brokers and 107 distinctive language brokers based mostly on USMLE instances. These brokers exhibit 23 biases, impacting diagnostic accuracy and patient-doctor interactions. GPT-4, the highest-performing mannequin, exhibits diminished accuracy (1.7%-2%) with cognitive biases and bigger reductions (1.5%) with implicit biases, affecting affected person follow-up willingness and confidence. Cross-communication between affected person and physician fashions improves accuracy. Restricted or extreme interplay time decreases accuracy, with a 27% discount at N=10 interactions and a 4%-9% discount at N>20 interactions. GPT-4V achieves round 27% accuracy in a multimodal medical atmosphere based mostly on NEJM instances.
Take a look at the Paper and Mission. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
When you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 42k+ ML SubReddit
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s keen about information science and machine studying, bringing a robust educational background and hands-on expertise in fixing real-life cross-domain challenges.








{kind=link}