
In machine studying, the main focus is commonly on enhancing the efficiency of enormous language fashions (LLMs) whereas decreasing the related coaching prices. This endeavor ceaselessly includes enhancing the standard of pretraining knowledge, as the information’s high quality immediately impacts the effectivity and effectiveness of the coaching course of. One distinguished technique to attain that is knowledge pruning, which includes choosing high-quality subsets from bigger datasets to coach the fashions extra successfully. This course of ensures that the fashions are saved from noisy and irrelevant knowledge, streamlining the coaching course of and enhancing general mannequin efficiency.
A problem in coaching LLMs is the presence of huge and infrequently noisy datasets. Poor-quality knowledge can considerably degrade the efficiency of those fashions, making it essential to develop strategies to filter out low-quality knowledge. The purpose is to retain solely probably the most related and high-quality data. Efficient knowledge pruning is crucial to optimize the coaching of those fashions, guaranteeing that solely the perfect knowledge is used and enhancing the mannequin’s accuracy and effectivity.
Conventional knowledge pruning strategies embody easy rules-based filtering and fundamental classifiers to determine high-quality samples. Whereas helpful, these strategies are sometimes restricted in dealing with large-scale and various datasets. Superior strategies have emerged, using neural network-based heuristics to evaluate knowledge high quality based mostly on numerous metrics resembling characteristic similarity or pattern issue. Regardless of their benefits, these strategies will be computationally costly and should not carry out persistently throughout totally different knowledge domains, necessitating the event of extra environment friendly and universally relevant strategies.
Researchers from Databricks, MIT, and DatologyAI have launched an progressive method to knowledge pruning utilizing small reference fashions to compute the perplexity of textual content samples. This method begins with coaching a small mannequin on a random subset of the information, which then evaluates the perplexity of every pattern. Perplexity, on this context, measures how nicely a likelihood mannequin predicts a pattern. Decrease perplexity scores point out higher-quality knowledge. By specializing in samples with the bottom perplexity scores, researchers can prune the dataset to retain solely probably the most related knowledge, thus enhancing the efficiency of the bigger fashions educated on this pruned knowledge.
The proposed technique includes splitting the dataset into coaching and validation units for the small reference mannequin. This mannequin is educated on the usual next-token prediction goal, computing perplexity scores for every pattern within the dataset. The dataset is then pruned based mostly on these scores, choosing samples inside a selected vary of perplexities. For instance, samples with the bottom perplexity are chosen utilizing a low choice criterion. This pruned dataset is subsequently used to coach the ultimate, bigger mannequin, which advantages from the high-quality knowledge. The effectiveness of this technique is demonstrated throughout totally different dataset compositions, together with the Pile, which consists of various curated domains, and Dolma, a dataset derived primarily from net scrapes.
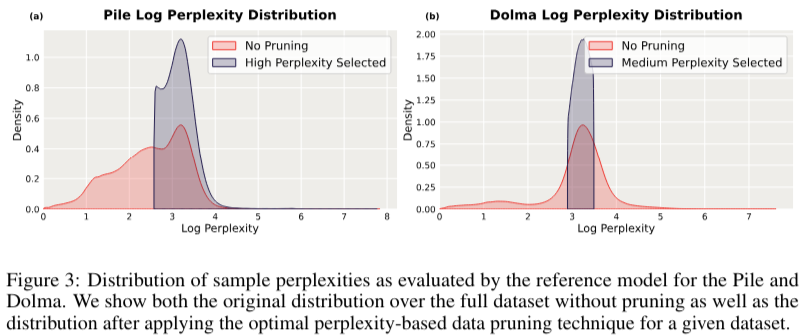
Perplexity-based knowledge pruning considerably improves the efficiency of LLMs on downstream duties. For example, pruning based mostly on perplexity scores computed with a 125 million parameter mannequin improved the common efficiency on downstream features of a 3 billion parameter mannequin by as much as 2.04%. Furthermore, it achieved as much as a 1.45 occasions discount in pretraining steps required to achieve comparable baseline efficiency. The strategy additionally proved efficient in numerous situations, together with over-trained and data-constrained regimes. In over-training situations, absolutely the acquire in common downstream normalized accuracy was comparable for each compute optimum and over-trained fashions, demonstrating the tactic’s robustness.
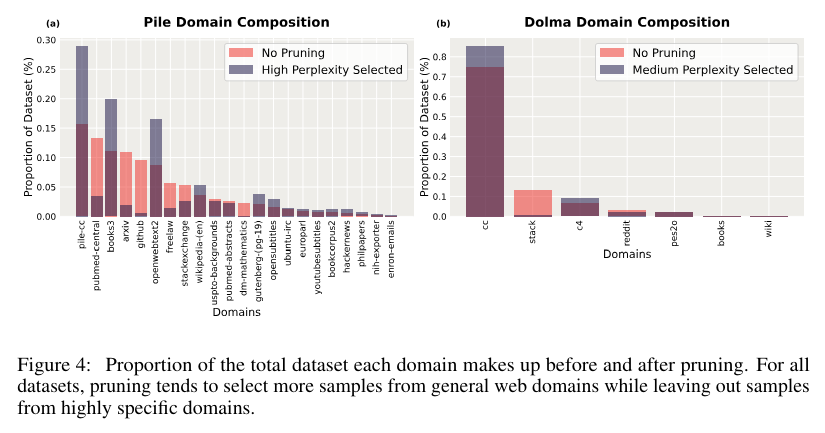
This analysis underscores the utility of small reference fashions in perplexity-based knowledge pruning, providing a major step ahead in optimizing LLM coaching. Researchers can enhance mannequin efficiency and coaching effectivity by leveraging smaller fashions to filter out low-quality knowledge. This technique presents a promising software for knowledge researchers, which confirmed a 1.89 enchancment in downstream efficiency for the Pile and 1.51 for Dolma when coaching for a compute optimum length. It enhances the efficiency of large-scale language fashions and reduces the computational assets required, making it a invaluable addition to the trendy knowledge researcher’s toolkit.

In conclusion, the examine presents a novel and efficient technique for knowledge pruning utilizing small reference fashions to compute perplexity. This method improves the efficiency & effectivity of enormous language fashions by guaranteeing high-quality pretraining knowledge. The strategy’s robustness throughout totally different knowledge compositions and coaching regimes highlights its potential as a main approach for contemporary knowledge analysis. By optimizing knowledge high quality, researchers can obtain higher mannequin efficiency with fewer assets, making perplexity-based knowledge pruning a invaluable approach for future developments in machine studying.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter. Be a part of our Telegram Channel, Discord Channel, and LinkedIn Group.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to hitch our 43k+ ML SubReddit | Additionally, take a look at our AI Occasions Platform
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.









{kind=link}