
Giant open-source pre-training datasets are necessary for the analysis group in exploring information engineering and growing clear, open-source fashions. Nonetheless, there’s a serious shift from frontier labs to coaching giant multimodal fashions (LMMs) that want giant datasets containing each pictures and texts. The capabilities of those frontier fashions are advancing rapidly, creating a big hole between the multimodal coaching information obtainable for closed and open-source fashions. Present open-source multimodal datasets are smaller and fewer numerous in comparison with text-only datasets, making it difficult to develop sturdy open-source LMMs and widening the hole in efficiency between open and closed-source fashions.
A few of the associated works mentioned on this paper are Multimodal Interleaved Knowledge, Giant Open-source Pre-training Datasets, and LMMs. Multimodal interleaved datasets have been first introduced in Flamingo and CM3. The primary open-source variations of those datasets have been Multimodal-C4 and OBELICS. Latest works like Chameleon and MM1 have scaled OBELICS to coach state-of-the-art multimodal fashions. The second method is the spine of open-source analysis and is necessary for coaching sturdy open-source multimodal fashions. In LMMs, researchers goal to pre-train language fashions utilizing large-scale multimodal interleaved and image-text datasets. This was launched by Flamingo and adopted by open-source fashions like OpenFlamingo, Idefics, and Emu.
Researchers from the College of Washington, Salesforce Analysis, Stanford College, the College of Texas at Austin, and the College of California, Berkeley have proposed Multimodal INTerleaved (MINT-1T). At present, MINT-1T is the most important and most numerous open-source multimodal interleaved dataset, which incorporates one trillion textual content tokens and three billion pictures, collected from varied sources resembling HTML, PDFs, and ArXiv. LLMs skilled on MINT-1T provide 10 occasions enchancment in scale and probably it outperform fashions skilled on the most effective present open-source dataset, OBELICS which incorporates a 115 billion textual content token dataset with 353M pictures sourced solely from HTML.
MINT-1T has created a big open-source dataset by accumulating numerous sources of combined paperwork, together with PDFs and ArXiv papers, and the ultimate dataset incorporates 965B HTML doc tokens, 51B PDF tokens, and 10B ArXiv tokens. For filtering textual content high quality, not utilizing model-based heuristics helps within the environment friendly scaling of tex-only fashions. This contains eliminating non-English paperwork utilizing Fasttext’s language identification mannequin with a confidence threshold of 0.65. Additional, paperwork containing URLs with NSFW substrings are eliminated to keep away from pornographic and undesirable content material, and textual content filtering strategies from RefinedWeb are utilized to take away paperwork with extreme duplicate n-grams.
To boost the efficiency of In-Context Studying, fashions are prompted with 1 to fifteen examples and executed a single trial per shot rely for every analysis benchmark. The outcomes present that the mannequin skilled on MINT-1T performs higher than the mannequin skilled on the HTML subset of MINT-1T for all photographs. Additional, MINT-1T fashions carry out equally to the OBELICS from 1 to 10 however outperform after 10 photographs. When evaluating efficiency on MMMU for every area, MINT-1T outperforms OBELICS and HTML baseline of MINT-1T, besides within the Enterprise area. The strategy exhibits enhanced efficiency in Science and Know-how domains because of the excessive illustration of those domains in ArXiv and PDF paperwork.
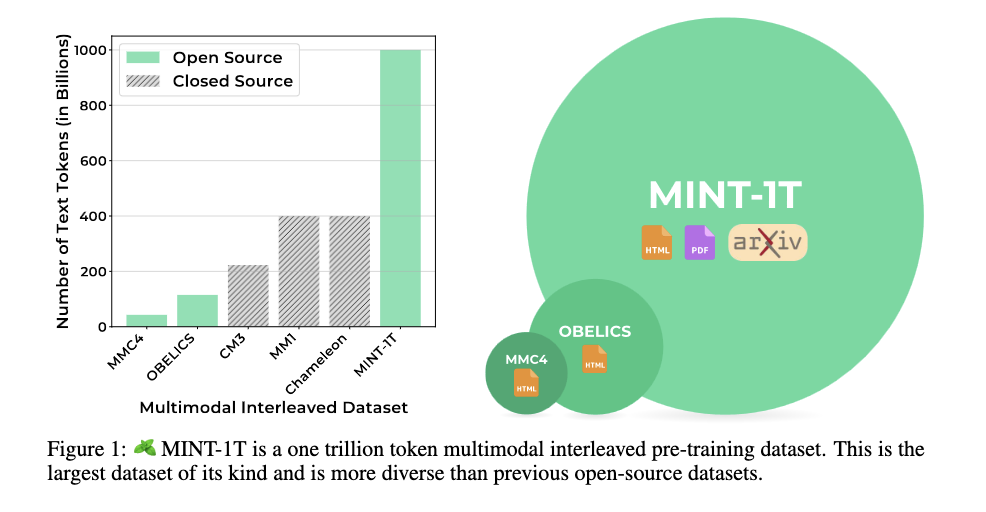
On this paper, researchers have launched MINT-1T, the primary open-source trillion token multimodal interleaved dataset and an necessary part for coaching giant multimodal fashions. This technique is a crucial useful resource for the analysis group to do open science on multimodal interleaved datasets. MINT-1T outperforms the earlier largest open-source dataset on this area, OBELICS that incorporates a 115 billion textual content token dataset with 353M pictures sourced solely from HTML. Future work contains coaching fashions on bigger subsets of MINT-1T, and growing multimodal doc filtering strategies to reinforce information high quality.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter.
Be part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Overlook to affix our 44k+ ML SubReddit

Sajjad Ansari is a last 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a deal with understanding the influence of AI applied sciences and their real-world implications. He goals to articulate advanced AI ideas in a transparent and accessible method.








{kind=link}