
Pure Language Processing (NLP) focuses on the interplay between computer systems and people by pure language. It encompasses duties comparable to translation, sentiment evaluation, and query answering, using giant language fashions (LLMs) to realize excessive accuracy and efficiency. LLMs are employed in quite a few functions, from automated buyer assist to content material technology, showcasing exceptional proficiency in various duties.
Evaluating giant language fashions (LLMs) is resource-intensive, requiring important computational energy, time, and monetary funding. The problem lies in effectively figuring out the top-performing fashions or strategies from a plethora of choices with out exhausting sources on full-scale evaluations. Practitioners usually should choose the optimum mannequin, immediate, or hyperparameters from a whole bunch of accessible selections for his or her particular wants. Conventional strategies contain evaluating a number of candidates on complete check units, which could be expensive and time-consuming.
Current approaches contain exhaustive analysis of fashions on complete datasets, which could possibly be cheaper. Strategies like immediate engineering and hyperparameter tuning necessitate in depth testing of a number of configurations to establish the best-performing setup, resulting in excessive useful resource consumption. For instance, the AlpacaEval undertaking benchmarks over 200 fashions towards a various set of 805 questions, requiring important investments in time and computing sources. Equally, evaluating 153 fashions within the Chatbot Area requires in depth computational energy, highlighting the inefficiency of present strategies.
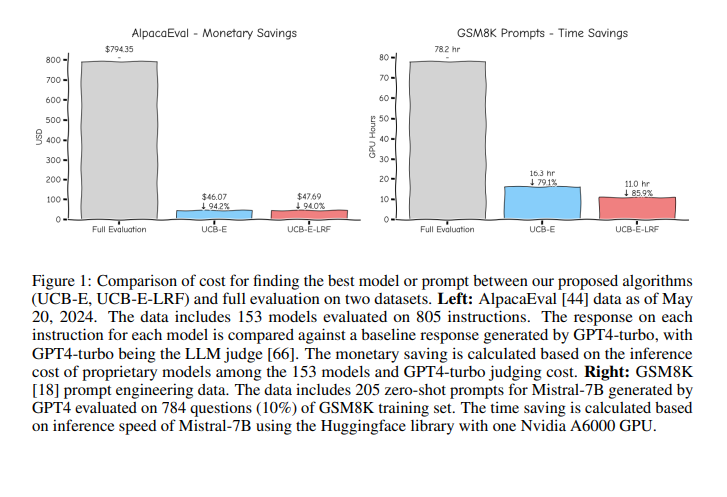
Researchers from Cornell College and the College of California, San Diego, launched two algorithms, UCB-E and UCB-E-LRF, leveraging multi-armed bandit frameworks mixed with low-rank factorization. These strategies dynamically allocate analysis sources, specializing in promising method-example pairs to considerably scale back the required evaluations and related prices. The multi-armed bandit strategy sequentially selects the subsequent method-example pair to judge based mostly on earlier evaluations, optimizing the choice course of.
The UCB-E algorithm extends classical multi-armed bandit rules to pick out probably the most promising method-example pairs for analysis based mostly on higher confidence bounds. At every step, it estimates the higher confidence sure of every methodology and picks the one with the very best sure for the subsequent analysis. This strategy ensures environment friendly useful resource allocation, specializing in strategies extra more likely to carry out effectively. UCB-E-LRF incorporates low-rank factorization to estimate unobserved scores, additional optimizing the choice course of and enhancing effectivity in figuring out the perfect methodology. By leveraging the intrinsic low-rankness of scoring matrices, UCB-E-LRF predicts the remaining unobserved method-example pairs and prioritizes evaluations of pairs with giant uncertainties.

The proposed algorithms considerably decreased analysis prices, figuring out top-performing strategies utilizing solely 5-15% of the required sources. Experiments confirmed an 85-95% discount in price in comparison with conventional exhaustive evaluations, proving the effectiveness and effectivity of those new approaches. For example, evaluating 205 zero-shot prompts on 784 GSM8K questions utilizing Mistral-7B required solely 78.2 Nvidia A6000 GPU hours, showcasing important useful resource financial savings. Moreover, UCB-E and UCB-E-LRF achieved excessive precision in figuring out the perfect strategies. UCB-E-LRF significantly exceling in tougher settings the place the tactic set is giant or efficiency gaps are small.
General, the analysis addresses the important downside of resource-intensive LLM evaluations by introducing environment friendly algorithms that scale back analysis prices whereas sustaining excessive accuracy in figuring out top-performing strategies. This development holds important potential for streamlining NLP mannequin improvement and deployment processes. By specializing in promising strategies and leveraging low-rank factorization, the researchers have supplied a strong resolution to the problem of environment friendly LLM analysis. This breakthrough can considerably influence the sector of NLP, enabling more practical and cost-efficient mannequin evaluations.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Overlook to affix our 46k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.









{kind=link}