
Lengthy-context understanding and retrieval-augmented technology (RAG) in giant language fashions (LLMs) is quickly advancing, pushed by the necessity for fashions that may deal with intensive textual content inputs and supply correct, environment friendly responses. These capabilities are important for processing giant volumes of data that can’t match right into a single immediate, which is essential for duties reminiscent of doc summarization, conversational query answering, and knowledge retrieval.
The efficiency hole between open-access LLMs and proprietary fashions like GPT-4-Turbo stays a big problem. Whereas open-access fashions like Llama-3-70B-Instruct and QWen2-72B-Instruct have enhanced their capabilities, they typically have to catch up in processing giant textual content volumes and retrieval duties. This hole is especially evident in real-world purposes, the place the flexibility to deal with long-context inputs and retrieve related info effectively is important. Present strategies for enhancing long-context understanding contain extending the context window of LLMs and using RAG. These methods complement one another, with long-context fashions excelling in summarizing giant paperwork and RAG effectively retrieving related info for particular queries. Nevertheless, current options typically undergo from context fragmentation and low recall charges, undermining their effectiveness.
Researchers from Nividia launched ChatQA 2, a Llama3-based mannequin developed to deal with these challenges. ChatQA 2 goals to bridge the hole between open-access and proprietary LLMs in long-context and RAG capabilities. By extending the context window to 128K tokens and utilizing a three-stage instruction tuning course of, ChatQA 2 considerably enhances instruction-following, RAG efficiency, and long-context understanding. This mannequin achieves a context window extension from 8K to 128K tokens by way of steady pretraining on a mixture of datasets, together with the SlimPajama dataset with upsampled lengthy sequences, leading to 10 billion tokens with a sequence size of 128K.
The know-how behind ChatQA 2 entails an in depth and reproducible technical recipe. The mannequin’s growth begins with extending the context window of Llama3-70B from 8K to 128K tokens by frequently pretraining it on a mixture of datasets. This course of makes use of a studying charge of 3e-5 and a batch measurement 32, coaching for 2000 steps to course of 8 billion tokens. Following this, a three-stage instruction tuning course of is utilized. The primary two levels contain coaching on high-quality instruction-following datasets and conversational QA knowledge with offered context. In distinction, the third stage focuses on long-context sequences as much as 128K tokens. This complete method ensures that ChatQA 2 can deal with varied duties successfully.
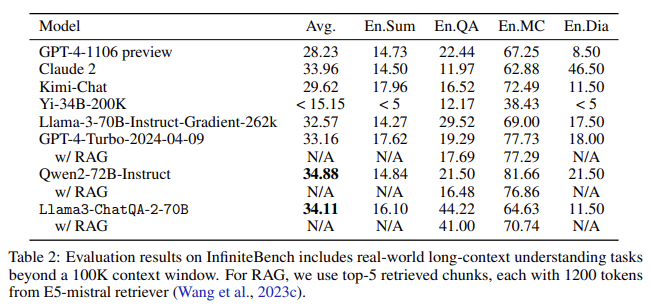
ChatQA 2 achieves accuracy akin to GPT-4-Turbo-2024-0409 on many long-context understanding duties and surpasses it in RAG benchmarks. As an illustration, within the InfiniteBench analysis, which incorporates features like longbook summarization, QA, multiple-choice, and dialogue, ChatQA 2 achieved a median rating of 34.11, near the very best rating of 34.88 by Qwen2-72B-Instruct. The mannequin additionally excels in medium-long context benchmarks inside 32K tokens, scoring 47.37, and short-context duties inside 4K tokens, attaining a median rating of 54.81. These outcomes spotlight ChatQA 2’s sturdy capabilities throughout totally different context lengths and features.
ChatQA 2 addresses vital points within the RAG pipeline, reminiscent of context fragmentation and low recall charges. The mannequin improves retrieval accuracy and effectivity by using a state-of-the-art long-context retriever. For instance, the E5-mistral embedding mannequin helps as much as 32K tokens for retrieval, considerably enhancing the mannequin’s efficiency on query-based duties. In comparisons between RAG and long-context options, ChatQA 2 persistently demonstrated superior outcomes, notably in features requiring intensive textual content processing.

In conclusion, ChatQA 2 by extending the context window to 128K tokens and implementing a three-stage instruction tuning course of, ChatQA 2 achieves GPT-4-Turbo-level capabilities in long-context understanding and RAG efficiency. This mannequin gives versatile options for varied downstream duties, balancing accuracy and effectivity by way of superior long-context and retrieval-augmented technology methods. The event and analysis of ChatQA 2 mark a vital step ahead in giant language fashions, offering enhanced capabilities for processing and retrieving info from intensive textual content inputs.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.









{kind=link}