
Aligning fashions with human preferences poses important challenges in AI analysis, notably in high-dimensional and sequential decision-making duties. Conventional Reinforcement Studying from Human Suggestions (RLHF) strategies require studying a reward perform from human suggestions after which optimizing this reward utilizing RL algorithms. This two-phase method is computationally advanced, typically resulting in excessive variance in coverage gradients and instability in dynamic programming, making it impractical for a lot of real-world purposes. Addressing these challenges is important for advancing AI applied sciences, particularly in fine-tuning giant language fashions and bettering robotic insurance policies.
Present RLHF strategies, reminiscent of these used for coaching giant language fashions and picture era fashions, usually study a reward perform from human suggestions after which use RL algorithms to optimize this perform. Whereas efficient, these strategies are based mostly on the idea that human preferences correlate straight with rewards. Latest analysis suggests this assumption is flawed, resulting in inefficient studying processes. Furthermore, RLHF strategies face important optimization challenges, together with excessive variance in coverage gradients and instability in dynamic programming, which limit their applicability to simplified settings like contextual bandits or low-dimensional state areas.
A crew of researchers from Stanford College, UT Austin and UMass Amherst introduce Contrastive Choice Studying (CPL), a novel algorithm that optimizes habits straight from human suggestions utilizing a regret-based mannequin of human preferences. CPL circumvents the necessity for studying a reward perform and subsequent RL optimization by leveraging the precept of most entropy. This method simplifies the method by straight studying the optimum coverage by a contrastive goal, making it relevant to high-dimensional and sequential decision-making issues. This innovation gives a extra scalable and computationally environment friendly answer in comparison with conventional RLHF strategies, broadening the scope of duties that may be successfully tackled utilizing human suggestions.
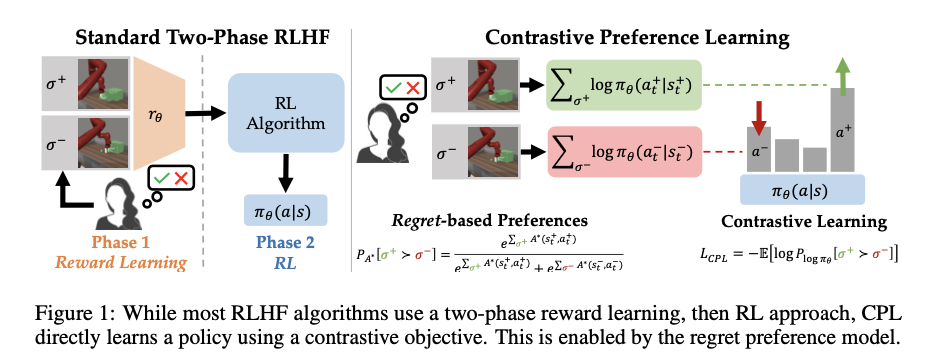
CPL relies on the utmost entropy precept, which results in a bijection between benefit features and insurance policies. By specializing in optimizing insurance policies fairly than benefits, CPL makes use of a easy contrastive goal to study from human preferences. The algorithm operates in an off-policy method, permitting it to make the most of arbitrary Markov Resolution Processes (MDPs) and deal with high-dimensional state and motion areas. The technical particulars embody the usage of a regret-based choice mannequin, the place human preferences are assumed to comply with the remorse underneath the person’s optimum coverage. This mannequin is built-in with a contrastive studying goal, enabling the direct optimization of insurance policies with out the computational overhead of RL.
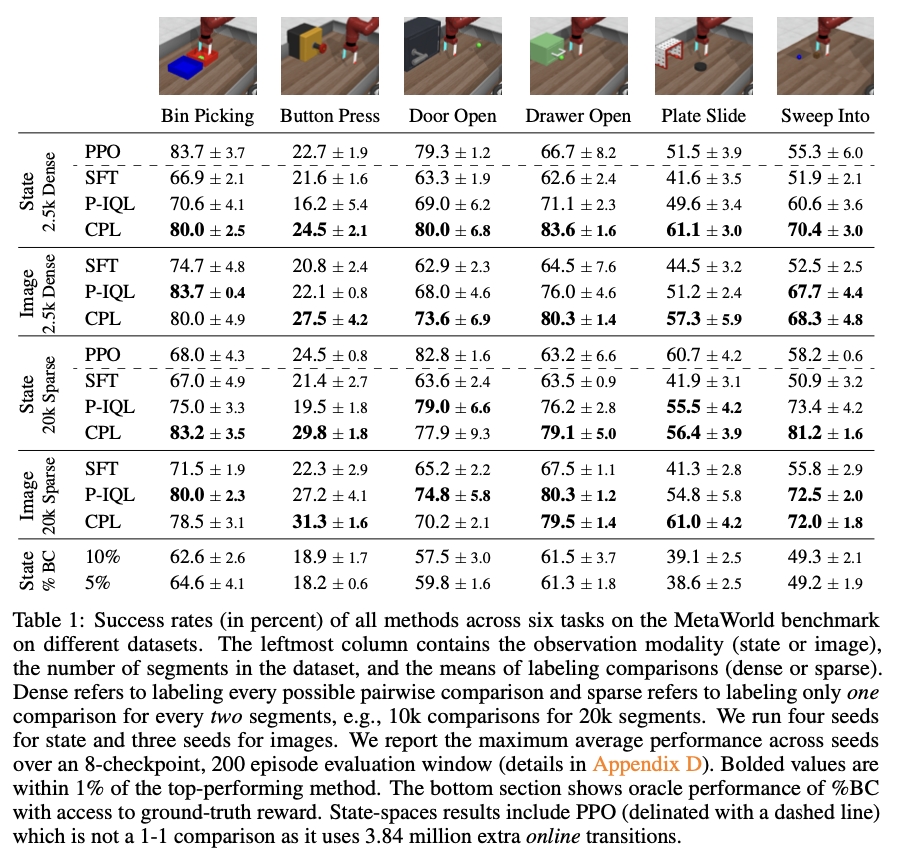
The analysis demonstrates CPL’s effectiveness in studying insurance policies from high-dimensional and sequential information. CPL not solely matches however typically surpasses conventional RL-based strategies. For example, in varied duties reminiscent of Bin Choosing and Drawer Opening, CPL achieved increased success charges in comparison with strategies like Supervised High-quality-Tuning (SFT) and Choice-based Implicit Q-learning (P-IQL). CPL additionally confirmed important enhancements in computational effectivity, being 1.6 instances sooner and 4 instances as parameter-efficient in comparison with P-IQL. Moreover, CPL demonstrated sturdy efficiency throughout various kinds of choice information, together with each dense and sparse comparisons, and successfully utilized high-dimensional picture observations, additional underscoring its scalability and applicability to advanced duties.
In conclusion, CPL represents a big development in studying from human suggestions, addressing the restrictions of conventional RLHF strategies. By straight optimizing insurance policies by a contrastive goal based mostly on a remorse choice mannequin, CPL gives a extra environment friendly and scalable answer for aligning fashions with human preferences. This method is especially impactful for high-dimensional and sequential duties, demonstrating improved efficiency and decreased computational complexity. These contributions are poised to affect the way forward for AI analysis, offering a strong framework for human-aligned studying throughout a broad vary of purposes.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. If you happen to like our work, you’ll love our e-newsletter..
Don’t Neglect to affix our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s enthusiastic about information science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.









{kind=link}