
Reinforcement studying (RL) is a specialised department of synthetic intelligence that trains brokers to make sequential choices by rewarding them for performing fascinating actions. This system is extensively utilized in robotics, gaming, and autonomous methods, permitting machines to develop complicated behaviors via trial and error. RL allows brokers to be taught from their interactions with the surroundings, adjusting their actions based mostly on suggestions to maximise cumulative rewards over time.
One of many important challenges in RL is addressing duties that require excessive ranges of abstraction and reasoning, akin to these offered by the Abstraction and Reasoning Corpus (ARC). The ARC benchmark, designed to check the summary reasoning skills of AI, poses a novel set of difficulties. It contains a huge motion area the place brokers should carry out a wide range of pixel-level manipulations, making it onerous to develop optimum methods. Moreover, defining success in ARC is non-trivial, requiring precisely replicating complicated grid patterns moderately than reaching a bodily location or endpoint. This complexity necessitates a deep understanding of process guidelines and exact software, complicating the reward system design.
Conventional approaches to ARC have primarily centered on program synthesis and leveraging massive language fashions (LLMs). Whereas these strategies have superior the sphere, they typically have to catch up as a result of logical complexities concerned in ARC duties. The efficiency of those fashions has but to fulfill expectations, main researchers to discover different approaches absolutely. Reinforcement studying has emerged as a promising but underexplored methodology for tackling ARC, providing a brand new perspective on addressing its distinctive challenges.
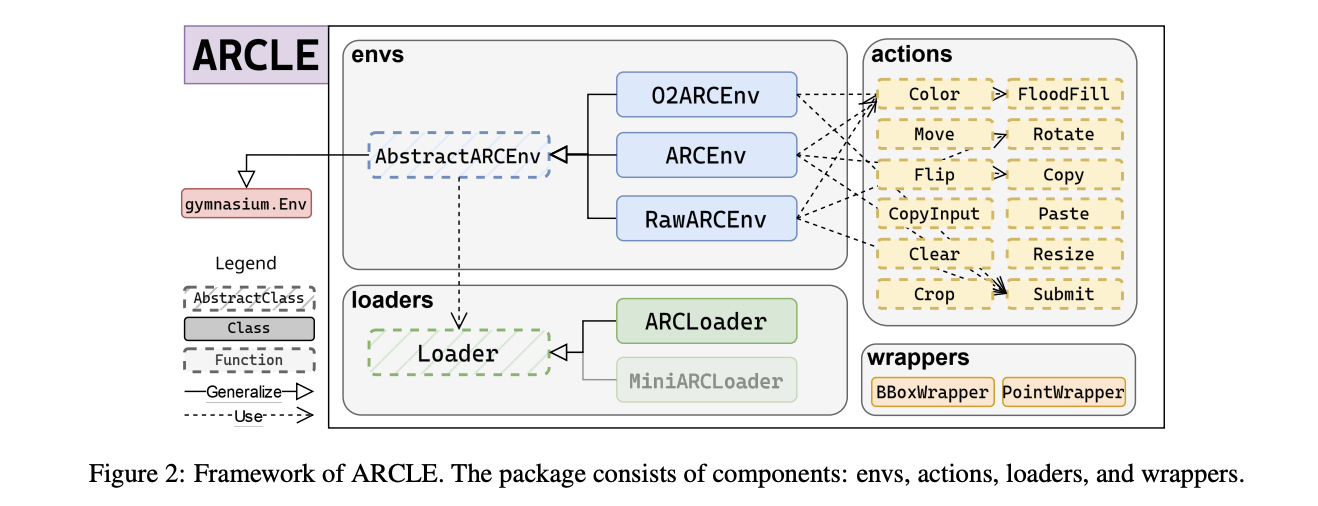
Researchers from the Gwangju Institute of Science and Know-how and Korea College have launched ARCLE (ARC Studying Surroundings) to handle these challenges. ARCLE is a specialised RL surroundings designed to facilitate analysis on ARC. It was developed utilizing the Gymnasium framework, offering a structured platform the place RL brokers can work together with ARC duties. This surroundings allows researchers to coach brokers utilizing reinforcement studying strategies particularly tailor-made for the complicated duties offered by ARC.
ARCLE includes a number of key elements: environments, loaders, actions, and wrappers. The surroundings part features a base class and its derivatives, which outline the construction of motion and state areas and user-definable strategies. The loaders part provides the ARC dataset to ARCLE environments, defining how datasets needs to be parsed and sampled. Actions in ARCLE are outlined to allow numerous grid manipulations, akin to coloring, transferring, and rotating pixels. These actions are designed to replicate the varieties of manipulations required to unravel ARC duties. The wrappers part modifies the surroundings’s motion or state area, enhancing the training course of by offering further functionalities.
The analysis demonstrated that RL brokers skilled inside ARCLE utilizing proximal coverage optimization (PPO) might efficiently be taught particular person duties. The introduction of non-factorial insurance policies and auxiliary losses considerably improved efficiency. These enhancements successfully mitigated points associated to navigating the huge motion area and attaining the hard-to-reach targets of ARC duties. The analysis highlighted that brokers geared up with these superior strategies confirmed marked enhancements in process efficiency. As an example, the PPO-based brokers achieved a excessive success price in fixing ARC duties when skilled with auxiliary loss capabilities that predicted earlier rewards, present rewards, and subsequent states. This multi-faceted strategy helped the brokers be taught extra successfully by offering further steering throughout coaching.
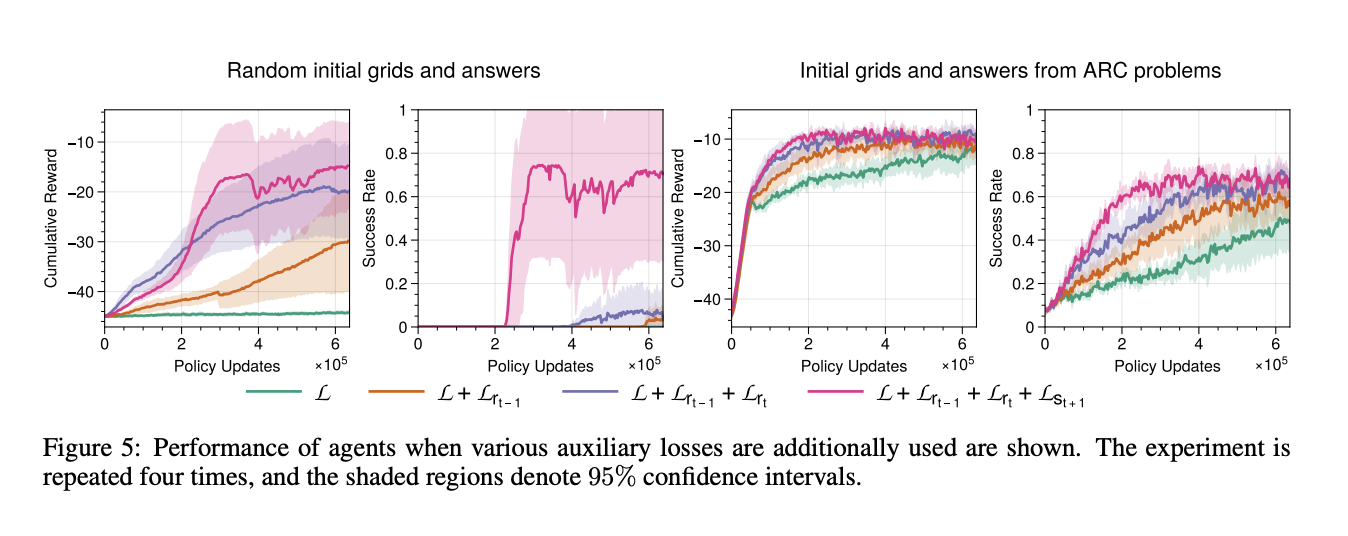
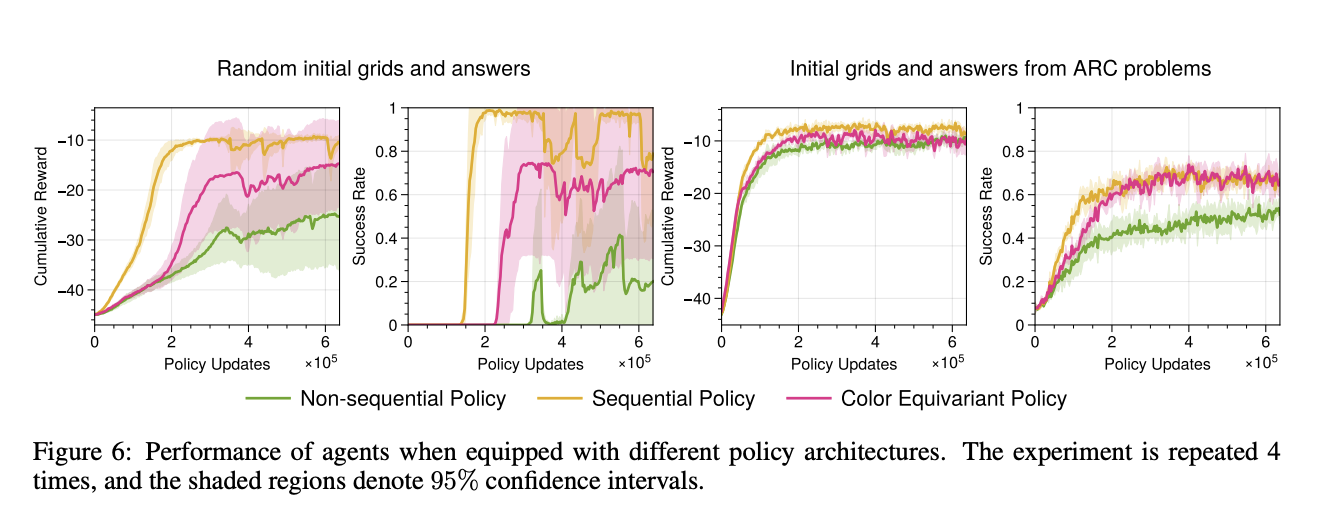
Brokers skilled with proximal coverage optimization (PPO) and enhanced with non-factorial insurance policies and auxiliary losses achieved a hit price exceeding 95% in random settings. The introduction of auxiliary losses, which included predicting earlier rewards, present rewards, and subsequent states, led to a marked improve in cumulative rewards and success charges. Efficiency metrics confirmed that brokers skilled with these strategies outperformed these with out auxiliary losses, attaining a 20-30% greater success price in complicated ARC duties.
To conclude, the analysis underscores the potential of ARCLE in advancing RL methods for summary reasoning duties. By making a devoted RL surroundings tailor-made to ARC, the researchers have paved the way in which for exploring superior RL strategies akin to meta-RL, generative fashions, and model-based RL. These methodologies promise to boost AI’s reasoning and abstraction capabilities additional, driving progress within the subject. The mixing of ARCLE into RL analysis addresses the present challenges of ARC and contributes to the broader endeavor of growing AI that may be taught, purpose, and summary successfully. This analysis invitations the RL neighborhood to have interaction with ARCLE and discover its potential for advancing AI analysis.
Try the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication..
Don’t Neglect to hitch our 47k+ ML SubReddit
Discover Upcoming AI Webinars right here
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.










{kind=link}