
Language fashions have gained prominence in reinforcement studying from human suggestions (RLHF), however present reward modeling approaches face challenges in precisely capturing human preferences. Conventional reward fashions, skilled as easy classifiers, wrestle to carry out express reasoning about response high quality, limiting their effectiveness in guiding LLM conduct. The first subject lies of their incapability to generate reasoning traces, forcing all evaluations to happen implicitly inside a single ahead go. This constraint hinders the mannequin’s capability to evaluate the nuances of human preferences totally. Whereas various approaches just like the LLM-as-a-Decide framework have tried to handle this limitation, they typically underperform basic reward fashions in pairwise desire classification duties, highlighting the necessity for a simpler methodology.
Researchers have tried numerous approaches to handle the challenges in reward modeling for language fashions. Rating fashions like Bradley-Terry and Plackett-Luce have been employed, however they wrestle with intransitive preferences. Some research instantly mannequin the chance of 1 response being most popular over one other, whereas others give attention to modeling rewards throughout a number of goals. Current work has proposed sustaining and coaching the language mannequin head as a type of regularization.
Critique-based suggestions strategies have additionally been explored, with some using self-generated critiques to enhance era high quality or function desire alerts. Nevertheless, these approaches differ from efforts to coach higher reward fashions when human desire knowledge is offered. Some researchers have investigated utilizing oracle critiques or human-labeled critique preferences to show language fashions to critique successfully.
The LLM-as-a-Decide framework, which makes use of a grading rubric to judge responses, shares similarities with critique-based strategies however focuses on analysis moderately than revision. Whereas this strategy produces chain-of-thought reasoning, it usually underperforms basic reward fashions in pairwise desire classification duties.
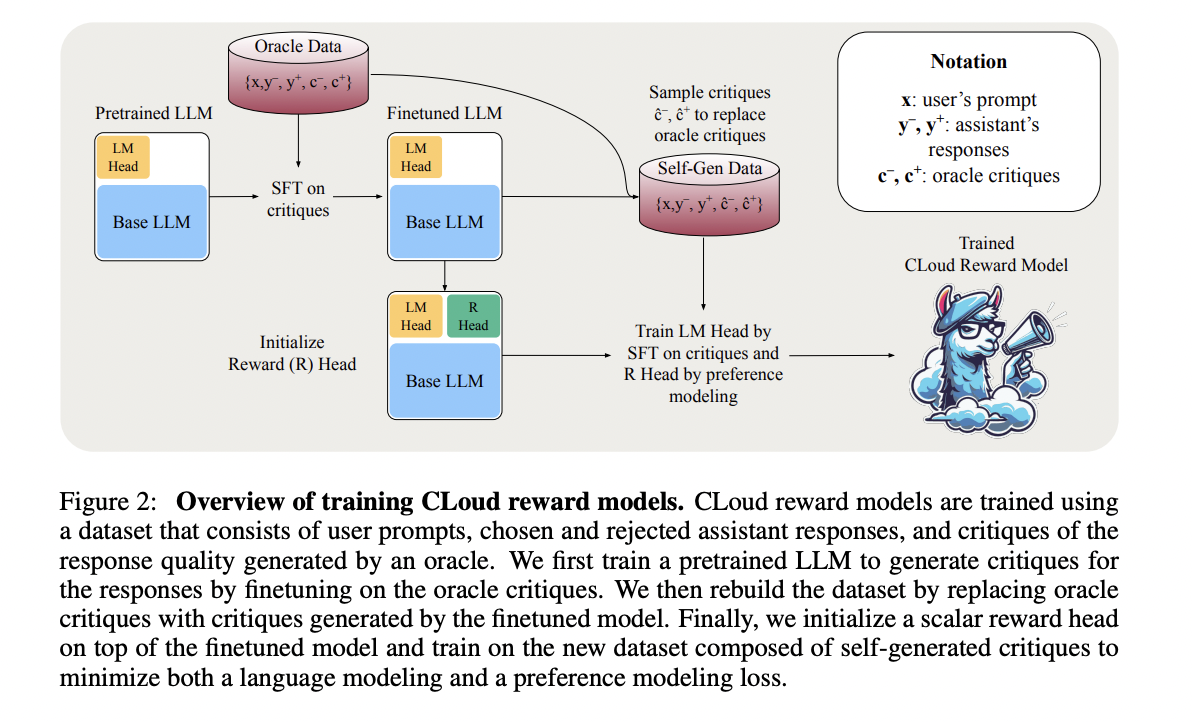
Researchers from Databricks, MIT, and the College of California, San Diego current Critique-out-Loud (CLoud) reward fashions, which characterize a novel strategy to bettering language mannequin efficiency in reinforcement studying from human suggestions. These fashions generate an in depth critique of how nicely an assistant’s response solutions a person’s question earlier than producing a scalar reward for the response high quality. This course of combines the strengths of basic reward fashions and the LLM-as-a-Decide framework.
CLoud reward fashions are skilled utilizing a desire dataset containing prompts, responses, and oracle critiques. The coaching course of includes supervised fine-tuning on oracle critiques for critique era and the Bradley-Terry desire mannequin for scalar reward manufacturing. To reinforce efficiency, the researchers discover multi-sample inference strategies, notably self-consistency, which includes sampling a number of critique-reward predictions and marginalizing throughout critiques for a extra correct reward estimate.
This revolutionary strategy goals to unify reward fashions and LLM-as-a-Decide strategies, doubtlessly resulting in important enhancements in pairwise desire classification accuracy and win charges in numerous benchmarks. The researchers additionally examine key design decisions, similar to on-policy versus off-policy coaching, and the advantages of self-consistency over critiques to optimize reward modeling efficiency.

CLoud reward fashions prolong basic reward fashions by incorporating a language modeling head alongside the bottom mannequin and reward head. The coaching course of includes supervised fine-tuning on oracle critiques, changing these with self-generated critiques, after which coaching the reward head on the self-generated critiques. This strategy minimizes the distribution shift between coaching and inference. The mannequin makes use of modified loss features, together with a Bradley-Terry mannequin loss and a critique-supervised fine-tuning loss. To reinforce efficiency, CLoud fashions can make use of self-consistency throughout inference, sampling a number of critiques for a prompt-response pair and averaging their predicted rewards for a closing estimate.
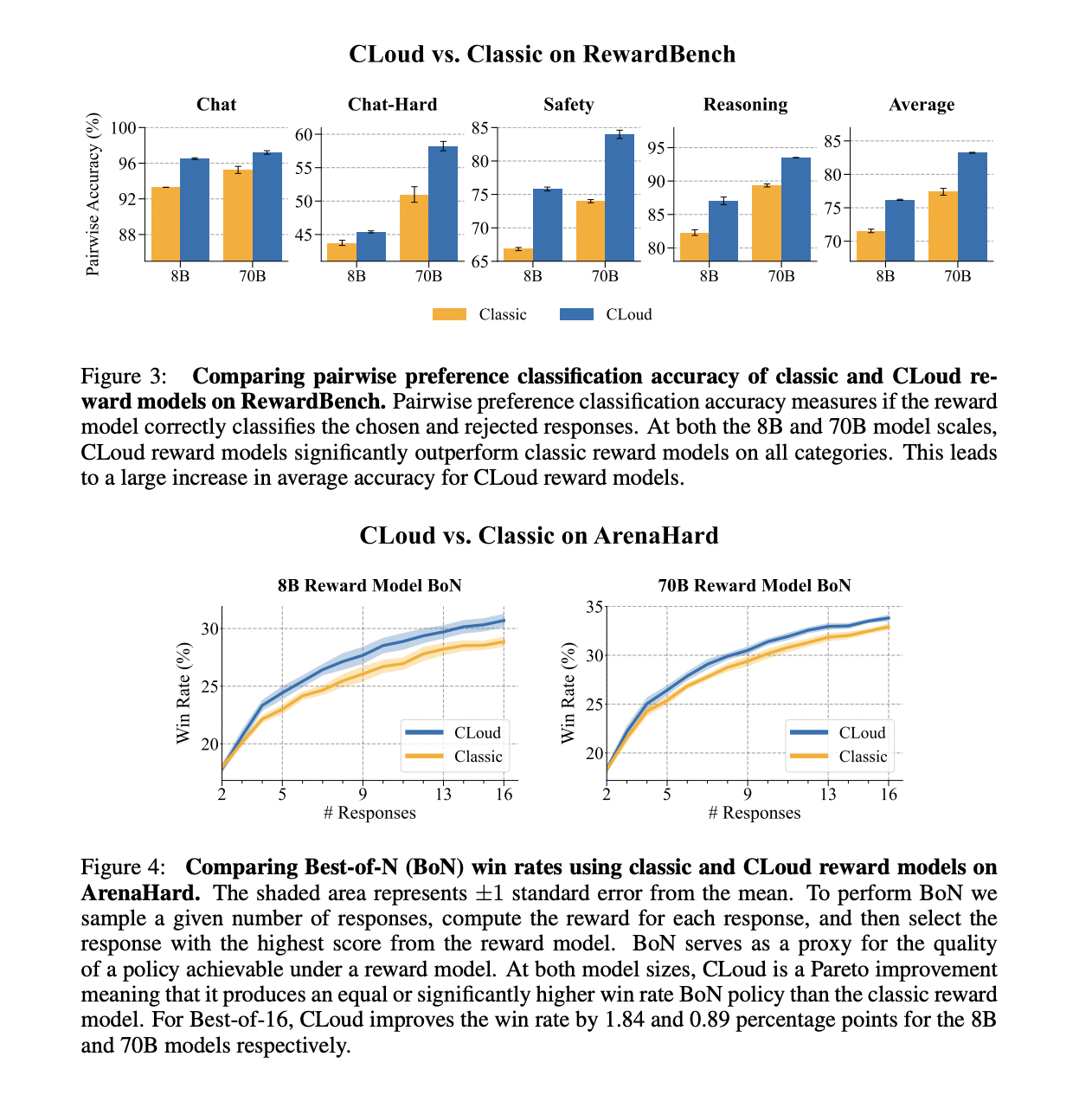
The researchers evaluated CLoud reward fashions towards basic reward fashions utilizing two key metrics: pairwise desire classification accuracy and Finest-of-N (BoN) win charge. For pairwise desire classification, they used the RewardBench analysis suite, which incorporates classes like Chat, Chat-Arduous, Security, and Reasoning. The BoN win charge was assessed utilizing ArenaHard, an open-ended era benchmark.
CLoud reward fashions considerably outperformed basic reward fashions in pairwise desire classification throughout all classes on RewardBench, for each 8B and 70B mannequin scales. This led to a considerable improve in common accuracy for CLoud fashions.
Within the BoN analysis on ArenaHard, CLoud fashions demonstrated a Pareto enchancment over basic fashions, producing equal or considerably increased win charges. For Finest-of-16, CLoud improved the win charge by 1.84 and 0.89 share factors for 8B and 70B fashions, respectively. These outcomes counsel that CLoud reward fashions provide superior efficiency in guiding language mannequin conduct in comparison with basic reward fashions.
This examine introduces CLoud reward fashions, which characterize a major development in desire modeling for language fashions. By preserving language modeling capabilities alongside a scalar reward head, these fashions explicitly cause about response high quality by means of critique era. This strategy demonstrates substantial enhancements over basic reward fashions in pairwise desire modeling accuracy and Finest-of-N decoding efficiency. Self-consistency decoding proved helpful for reasoning duties, notably these with quick reasoning horizons. By unifying language era with desire modeling, CLoud reward fashions set up a brand new paradigm that opens avenues for bettering reward fashions by means of variable inference computing, laying the groundwork for extra subtle and efficient desire modeling in language mannequin growth.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. In case you like our work, you’ll love our publication..
Don’t Overlook to affix our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here
Asjad is an intern advisor at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.









{kind=link}