
Precisely transcribing spoken language into written textual content is changing into more and more important in speech recognition. This know-how is essential for accessibility providers, language processing, and medical assessments. Nonetheless, the problem lies in capturing the phrases and the intricate particulars of human speech, together with pauses, filler phrases, and different disfluencies. These nuances present worthwhile insights into cognitive processes and are significantly vital in medical settings the place correct speech evaluation can assist in diagnosing and monitoring speech-related issues. Because the demand for extra exact transcription grows, so does the necessity for progressive strategies to deal with these challenges successfully.
One of the crucial important challenges on this area is the precision of word-level timestamps. That is particularly vital in eventualities with a number of audio system or background noise, the place conventional strategies usually want to enhance. Correct transcription of disfluencies, equivalent to stuffed pauses, phrase repetitions, and corrections, is troublesome but essential. These parts should not mere speech artifacts; they mirror underlying cognitive processes and are key indicators in assessing circumstances like aphasia. Present transcription fashions usually need assistance with these nuances, resulting in errors in each transcription and timing. These inaccuracies restrict their effectiveness, significantly in medical and different high-stakes environments the place precision is paramount.
Present strategies, just like the Whisper and WhisperX fashions, try and sort out these challenges utilizing superior methods equivalent to pressured alignment and dynamic time warping (DTW). WhisperX, as an illustration, employs a VAD-based cut-and-merge strategy that enhances each velocity and accuracy by segmenting audio earlier than transcription. Whereas this methodology affords some enhancements, it nonetheless faces important challenges in noisy environments and with advanced speech patterns. The reliance on a number of fashions, like WhisperX’s use of Wav2Vec2.0 for phoneme alignment, provides complexity and may result in additional degradation of timestamp precision in less-than-ideal circumstances. Regardless of these developments, there stays a transparent want for extra strong options.
Researchers at Nyra Well being launched a brand new mannequin, CrisperWhisper. This mannequin refined the Whisper structure, enhancing noise robustness and single-speaker focus. The researchers considerably enhanced word-level timestamps’ accuracy by rigorously adjusting the tokenizer and fine-tuning the mannequin. CrisperWhisper employs a dynamic time-warping algorithm that aligns speech segments with larger precision, even in background noise. This adjustment improves the mannequin’s efficiency in noisy environments and reduces errors in transcribing disfluencies, making it significantly helpful for medical functions.

CrisperWhisper’s enhancements are largely on account of a number of key improvements. The mannequin strips pointless tokens and optimizes the vocabulary to detect higher pauses and filler phrases, equivalent to ‘uh’ and ‘um.’ It introduces heuristics that cap pause durations at 160 ms, distinguishing between significant speech pauses and insignificant artifacts. CrisperWhisper employs a price matrix constructed from normalized cross-attention vectors to make sure that every phrase’s timestamp is as correct as attainable. This methodology permits the mannequin to supply transcriptions that aren’t solely extra exact but additionally extra dependable in noisy circumstances. The result’s a mannequin that may precisely seize the timing of speech, which is essential for functions that require detailed speech evaluation.
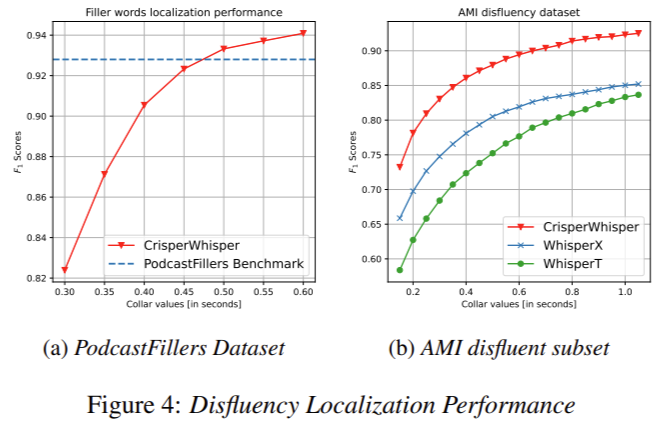
The efficiency of CrisperWhisper is spectacular when in comparison with earlier fashions. It achieves an F1 rating of 0.975 on the artificial dataset and considerably outperforms WhisperX and WhisperT in noise robustness and phrase segmentation accuracy. As an illustration, CrisperWhisper achieves an F1 rating of 0.90 on the AMI disfluency subset, in comparison with WhisperX’s 0.85. The mannequin additionally demonstrates superior noise resilience, sustaining excessive mIoU and F1 scores even beneath circumstances with a signal-to-noise ratio of 1:5. In checks involving verbatim transcription datasets, CrisperWhisper lowered the phrase error fee (WER) on the AMI Assembly Corpus from 16.82% to 9.72%, and on the TED-LIUM dataset from 11.77% to 4.01%. These outcomes underscore the mannequin’s functionality to ship exact and dependable transcriptions, even in difficult environments.

In conclusion, Nyra Well being launched CrisperWhisper, which addresses timestamp accuracy and noise robustness. CrisperWhisper supplies a strong answer that enhances the precision of speech transcriptions. Its skill to precisely seize disfluencies and keep excessive efficiency in noisy circumstances makes it a worthwhile instrument for varied functions, significantly in medical settings. The enhancements in phrase error fee and total transcription accuracy spotlight CrisperWhisper’s potential to set a brand new normal in speech recognition know-how.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to comply with us on Twitter and LinkedIn. Be part of our Telegram Channel. If you happen to like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.









{kind=link}