
Integrating superior predictive fashions into autonomous driving programs has turn out to be essential for enhancing security and effectivity. Digital camera-based video prediction emerges as a pivotal part, providing wealthy real-world information. Content material generated by synthetic intelligence is presently a number one space of research inside the domains of laptop imaginative and prescient and synthetic intelligence. Nonetheless, producing photo-realistic and coherent movies poses important challenges as a result of restricted reminiscence and computation time. Furthermore, predicting video from a front-facing digital camera is vital for superior driver-assistance programs in autonomous autos.
Current approaches embody diffusion-based architectures which have turn out to be in style for producing photographs and movies, with higher efficiency in duties reminiscent of picture technology, modifying, and translation. Different strategies like Generative Adversarial Networks (GANs), flow-based fashions, auto-regressive fashions, and Variational Autoencoders (VAEs) have additionally been used for video technology and prediction. Denoising Diffusion Probabilistic Fashions (DDPMs) outperform conventional technology fashions in effectiveness. Nonetheless, producing lengthy movies continues to be computationally demanding. Though autoregressive fashions like Phenaki deal with this subject, they typically face challenges with unrealistic scene transitions and inconsistencies in longer sequences.
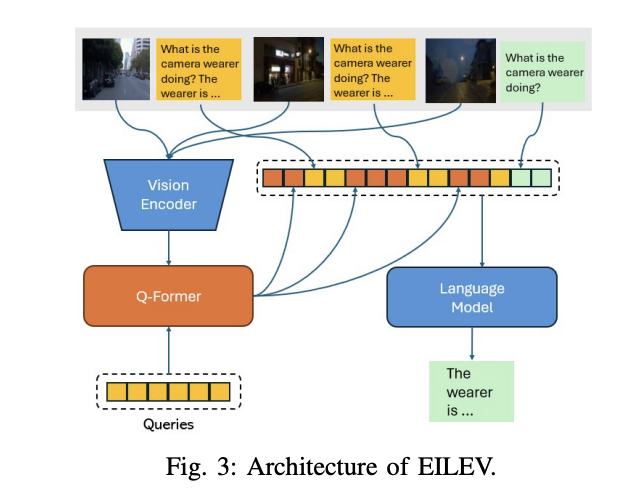
A crew of researchers from Columbia College in New York have proposed the DriveGenVLM framework to generate driving movies and used Imaginative and prescient Language Fashions (VLMs) to grasp them. The framework makes use of a video technology strategy based mostly on denoising diffusion probabilistic fashions (DDPM) to foretell real-world video sequences. A pre-trained mannequin known as Environment friendly In-context Studying on Selfish Movies (EILEV) is utilized to guage the adequacy of generated movies for VLMs. EILEV additionally supplies narrations for these generated movies, doubtlessly enhancing site visitors scene understanding, aiding navigation, and bettering planning capabilities in autonomous driving.
The DriveGenVLM framework is validated utilizing the Waymo Open Dataset, which supplies various real-world driving eventualities from a number of cities. The dataset is cut up into 108 movies for coaching and divided equally among the many three cameras, and 30 movies for testing (10 per digital camera). This framework makes use of the Frechet Video Distance (FVD) metric to guage the standard of generated movies, the place FVD measures the similarity between the distributions of generated and actual movies. This metric is efficacious for temporal coherence and visible high quality analysis, making it an efficient instrument for benchmarking video synthesis fashions in duties reminiscent of video technology and future body prediction.
The outcomes for the DriveGenVLM framework on the Waymo Open Dataset for 3 cameras reveal that the adaptive hierarchy-2 sampling technique outperforms different sampling schemes by yielding the bottom FVD scores. Prediction movies are generated for every digital camera utilizing this superior sampling technique, the place every instance is conditioned on the primary 40 frames, with floor reality frames and predicted frames. Furthermore, the versatile diffusion mannequin’s coaching on the Waymo dataset reveals its capability for producing coherent and photorealistic movies. Nonetheless, it nonetheless faces challenges in precisely decoding complicated real-world driving eventualities, reminiscent of navigating site visitors and pedestrians.

In conclusion, researchers from Columbia College have launched the DriveGenVLM framework to generate driving movies. The DDPM educated on the Waymo dataset is proficient whereas producing coherent and lifelike photographs from entrance and facet cameras. Furthermore, the pre-trained EILEV mannequin is used to generate motion narrations for the movies. The DriveGenVLM framework highlights the potential of integrating generative fashions and VLMs for autonomous driving duties. Sooner or later, the generated descriptions of driving eventualities can be utilized in giant language fashions to supply driver help or assist language model-based algorithms.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and LinkedIn. Be a part of our Telegram Channel.
When you like our work, you’ll love our publication..
Don’t Overlook to hitch our 50k+ ML SubReddit

Sajjad Ansari is a closing yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible functions of AI with a concentrate on understanding the influence of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.









{kind=link}