
AI has seen vital progress in coding, arithmetic, and reasoning duties. These developments are pushed largely by the elevated use of enormous language fashions (LLMs), important for automating advanced problem-solving duties. These fashions are more and more used to deal with extremely specialised and structured issues in aggressive programming, mathematical proofs, and real-world coding points. This speedy evolution is remodeling how AI is utilized throughout industries, showcasing the potential to handle tough computational duties requiring deep studying fashions to grasp and precisely resolve these challenges.
One of many key challenges that AI fashions face is optimizing their efficiency throughout inference, which is the stage the place fashions generate options based mostly on given inputs. In most situations, LLMs are solely given one alternative to unravel an issue, leading to missed alternatives to reach at appropriate options. This limitation stays regardless of vital investments in coaching fashions on giant datasets and enhancing their capability to deal with reasoning and problem-solving. The core subject is the restricted compute assets allotted throughout inference. Researchers have lengthy realized that coaching bigger fashions has led to enhancements, however inference, the method the place fashions apply what they’ve discovered, nonetheless lags behind optimization and effectivity. Consequently, this bottleneck limits the total potential of AI in high-stakes, real-world duties like coding competitions and formal verification issues.
Varied computational strategies have been used to handle this hole and enhance inference. One common strategy is to scale up mannequin measurement or to make use of strategies corresponding to chain-of-thought prompting, the place fashions generate step-by-step reasoning earlier than delivering their closing solutions. Whereas these strategies do enhance accuracy, they arrive at a major price. Bigger fashions and superior inference strategies require extra computational assets and longer processing occasions, that are solely generally sensible. As a result of fashions are sometimes constrained to creating only one try at fixing an issue, they must be allowed to discover totally different answer paths absolutely. For instance, state-of-the-art fashions like GPT-4o and Claude 3.5 Sonnet might produce a high-quality answer on the primary strive, however the excessive prices related to their use restrict their scalability.
Researchers from Stanford College, College of Oxford, and Google DeepMind launched a novel answer to those limitations referred to as “repeated sampling.” This strategy entails producing a number of options for an issue and utilizing domain-specific instruments, corresponding to unit assessments or proof verifiers, to pick out the most effective reply. Within the repeated sampling strategy, the AI generates quite a few outputs. As a substitute of counting on only one, researchers evaluation a batch of generated options after which apply a verifier to select the proper one. This methodology shifts the main focus from requiring probably the most highly effective mannequin for a single try and maximizing the chance of success by means of a number of tries. Curiously, the method reveals that weaker fashions could be amplified by means of repeated sampling, usually exceeding the efficiency of stronger fashions on a single-attempt foundation. The researchers apply this methodology to duties starting from aggressive coding to formal arithmetic, proving the cost-effectiveness and effectivity of the strategy.
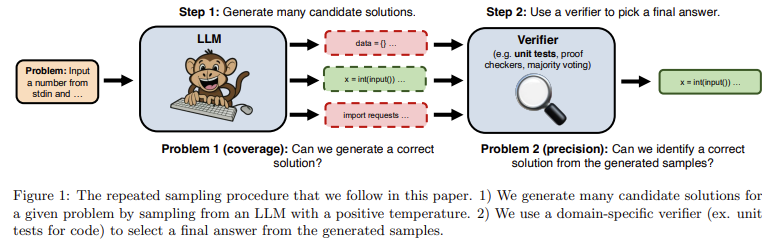
One of many key technical facets of this repeated sampling methodology is the flexibility to scale the variety of generated options and systematically slender down the most effective ones. The approach works particularly nicely in domains the place verification is simple, corresponding to coding, the place unit assessments can rapidly determine whether or not an answer is appropriate. For instance, in coding competitions, researchers used repeated sampling on the CodeContests dataset, which consists of coding issues that require fashions to output appropriate Python3 applications. Right here, the researchers generated as many as 10,000 makes an attempt per downside, resulting in vital efficiency positive aspects. Specifically, the protection, or the fraction of the problems solved by any pattern, elevated considerably because the variety of samples grew. For example, with the Gemma-2B mannequin, the success fee elevated from 0.02% on the primary try and 7.1% when samples reached 10,000. Related patterns had been noticed with Llama-3 fashions, the place the protection rose exponentially because the variety of makes an attempt scaled up, displaying that even weaker fashions might outperform stronger ones when given adequate alternatives.
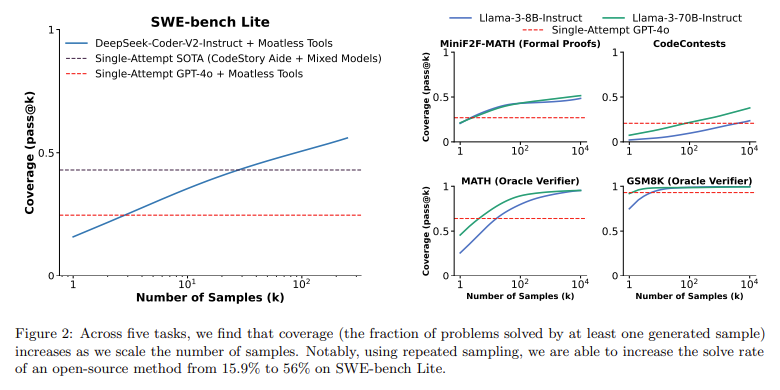
The efficiency advantages of repeated sampling had been particularly notable within the SWE-bench Lite dataset, which consists of real-world GitHub points the place fashions should modify codebases and confirm their options with automated unit assessments. By permitting a mannequin like DeepSeek-V2-Coder-Instruct to make 250 makes an attempt, researchers had been in a position to resolve 56% of the coding points, surpassing the single-attempt state-of-the-art efficiency of 43% achieved by extra highly effective fashions corresponding to GPT-4o and Claude 3.5 Sonnet. This enchancment reveals the benefits of making use of a number of samples somewhat than counting on a single, costly answer try. In sensible phrases, sampling 5 occasions from the cheaper DeepSeek mannequin was cheaper than utilizing a single pattern from premium fashions like GPT-4o or Claude whereas additionally fixing extra issues.
Past coding and formal proof issues, repeated sampling additionally demonstrated promise in fixing mathematical phrase issues. In settings the place automated verifiers, corresponding to proof checkers or unit assessments, are unavailable, researchers famous a spot between protection and the flexibility to select the proper answer from a set of generated samples. In duties just like the MATH dataset, Llama-3 fashions achieved 95.3% protection with 10,000 samples. Nonetheless, frequent strategies for choosing the proper answer, corresponding to majority voting or reward fashions, plateaued past a couple of hundred samples and wanted to scale with the sampling price range absolutely. These outcomes point out that whereas repeated sampling can generate many appropriate options, figuring out the proper one stays difficult in domains the place options can’t be verified robotically.
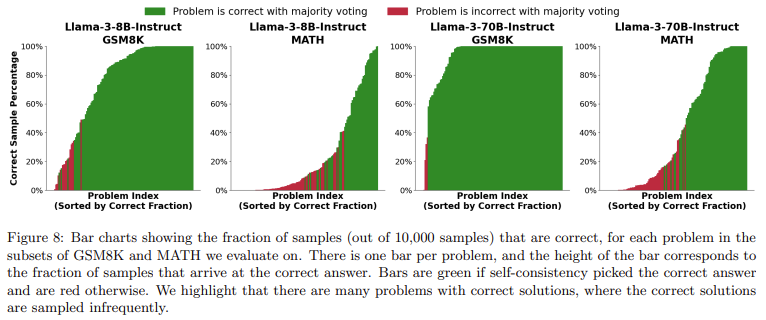
Researchers discovered that the connection between protection and the variety of samples adopted a log-linear development usually. This conduct was modeled utilizing an exponentiated energy regulation, offering insights into how inference computes scales with the variety of samples. In easier phrases, as fashions generate extra makes an attempt, the chance of fixing the issue will increase predictably. This sample held throughout varied fashions, together with Llama-3, Gemma, and Pythia, which ranged from 70M to 70B parameters. Protection grew constantly with the variety of samples, even in smaller fashions like Pythia-160M, the place protection improved from 0.27% with one try and 57% with 10,000 samples. The repeated sampling methodology proved adaptable throughout varied duties and mannequin sizes, reinforcing its versatility for enhancing AI efficiency.

In conclusion, the researchers culminated that repeated sampling enhances downside protection and provides a cheap various to utilizing dearer, highly effective fashions. Their experiments confirmed that amplifying a weaker mannequin by means of repeated sampling might usually yield higher outcomes than counting on a single try from a extra succesful mannequin. For example, utilizing the DeepSeek mannequin with a number of samples decreased the general computation prices and improved efficiency metrics, fixing extra points than fashions like GPT-4o. Whereas repeated sampling is very efficient in duties the place verifiers can robotically determine appropriate options, it additionally highlights the necessity for higher verification strategies in domains with out such instruments.
Take a look at the Paper, Dataset, and Undertaking. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and LinkedIn. Be a part of our Telegram Channel.
If you happen to like our work, you’ll love our publication..
Don’t Overlook to affix our 50k+ ML SubReddit
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.









{kind=link}