
Synthetic intelligence (AI) and pure language processing (NLP) have seen important developments lately, significantly within the improvement and deployment of huge language fashions (LLMs). These fashions are important for numerous duties, comparable to textual content technology, query answering, and doc summarization. Nonetheless, whereas LLMs have demonstrated exceptional capabilities, they encounter limitations when processing lengthy enter sequences. The fastened context home windows inherent in most fashions constrain their capability to deal with massive datasets, which may negatively influence their efficiency in duties requiring the retention of advanced and extensively distributed info. This problem necessitates the event of revolutionary strategies to increase the fashions’ efficient context home windows with out sacrificing efficiency or requiring extreme computational assets.
LLMs’ key subject is sustaining accuracy when coping with massive quantities of enter information, particularly in retrieval-oriented duties. Because the enter measurement will increase, the fashions typically wrestle to concentrate on related info, resulting in a deterioration in efficiency. The duty turns into extra advanced when essential info is buried inside irrelevant or much less necessary information. With a mechanism to information the mannequin towards the important elements of the enter, important computational assets are sometimes spent processing pointless sections. Conventional approaches to dealing with lengthy contexts, comparable to merely growing the context window measurement, are computationally costly and don’t all the time yield the specified enhancements in efficiency.
A number of strategies have been proposed to handle these limitations. Some of the frequent approaches is sparse consideration, which selectively focuses the mannequin’s consideration on smaller subsets of the enter, lowering the computational load. Different methods embody size extrapolation, which makes an attempt to increase the mannequin’s efficient enter size with out dramatically growing its computational complexity. Methods comparable to context compression, which condenses crucial info in a given textual content, have additionally been employed. Prompting methods like Chain of Thought (CoT) break down advanced duties into smaller, extra manageable steps. These approaches have achieved various ranges of success however are sometimes accompanied by trade-offs between computational effectivity and mannequin accuracy.
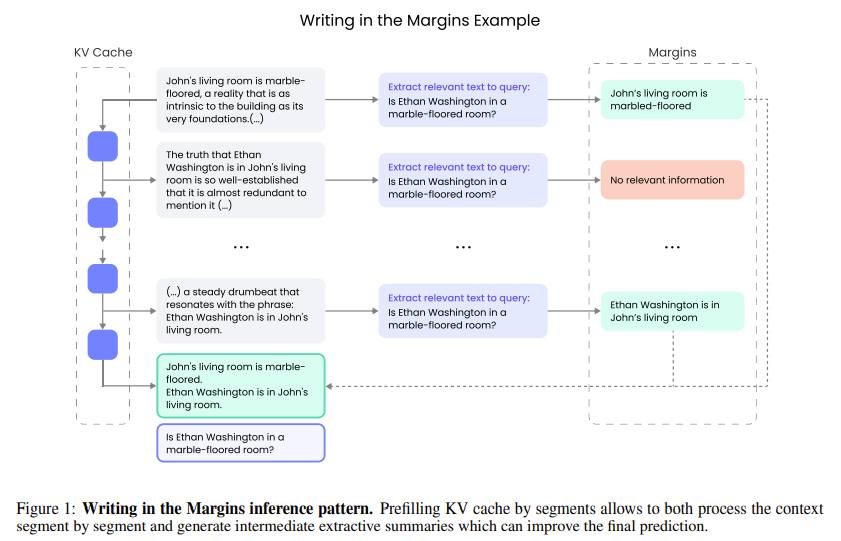
Researchers at Author, Inc. launched a brand new inference sample known as Writing within the Margins (WiM). This technique goals to optimize the efficiency of LLMs on duties requiring long-context retrieval by leveraging an revolutionary segment-wise processing method. As a substitute of concurrently processing your entire enter sequence, WiM breaks the context into smaller, manageable chunks. Throughout every chunk’s processing, intermediate margin notes information the mannequin. These notes assist the mannequin establish related info and make extra knowledgeable predictions. By incorporating this segment-wise method, WiM considerably improves the mannequin’s effectivity and accuracy with out requiring fine-tuning.
The WiM technique divides the enter into fixed-size chunks throughout the prefill part. This permits the mannequin’s key-value (KV) cache to be populated incrementally, enabling the mannequin to course of the enter extra effectively. This course of generates margin notes, that are query-based extractive summaries. These notes are then reintegrated into the ultimate output, offering the mannequin with extra detailed info to information its reasoning. This method minimizes computational overhead whereas enhancing the mannequin’s comprehension of lengthy contexts. The researchers discovered that this technique improves the mannequin’s efficiency and will increase the transparency of its decision-making course of, as end-users can view the margin notes and perceive how the mannequin arrives at its conclusions.
When it comes to efficiency, WiM delivers spectacular outcomes throughout a number of benchmarks. For reasoning duties like HotpotQA and MultiHop-RAG, the WiM technique improves the mannequin’s accuracy by a median of seven.5%. Extra notably, for duties involving information aggregation, such because the Widespread Phrases Extraction (CWE) benchmark, WiM delivers greater than a 30% improve within the F1-score, demonstrating its effectiveness in duties that require the mannequin to synthesize info from massive datasets. The researchers reported that WiM provides a big benefit in real-time functions, because it reduces the latency of the mannequin’s responses by enabling customers to view progress because the enter is being processed. This characteristic permits for an early exit from the processing part if a passable reply is discovered earlier than your entire enter is processed.

The researchers additionally carried out WiM utilizing the Hugging Face Transformers library, making it accessible to a broader viewers of AI builders. By releasing the code as open-source, they encourage additional experimentation and improvement of the WiM technique. This technique aligns with the rising development of creating AI instruments extra clear and explainable. The power to view intermediate outcomes, comparable to margin notes, makes it simpler for customers to belief the mannequin’s choices, as they will perceive the reasoning behind its output. In sensible phrases, this may be particularly beneficial in fields like authorized doc evaluation or educational analysis, the place the transparency of AI choices is essential.

In conclusion, Writing within the Margins provides a novel and efficient resolution to LLMs’ most important challenges: the flexibility to deal with lengthy contexts with out sacrificing efficiency. By introducing segment-wise processing and the technology of margin notes, the WiM technique will increase accuracy and effectivity in long-context duties. It improves reasoning talents, as evidenced by a 7.5% accuracy enhance in multi-hop reasoning duties, and excels in aggregation duties, with a 30% improve in F1-score for CWE. Furthermore, WiM supplies transparency in AI decision-making, making it a beneficial device for functions that require explainable outcomes. The success of WiM means that it’s a promising path for future analysis, significantly as AI continues to be utilized to more and more advanced duties that require the processing of intensive datasets.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our publication..
Don’t Neglect to hitch our 50k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.









{kind=link}