
Giant language fashions (LLMs) are more and more utilized in domains requiring complicated reasoning, resembling mathematical problem-solving and coding. These fashions can generate correct outputs in a number of domains. Nevertheless, an important facet of their improvement is their capacity to self-correct errors with out exterior enter, intrinsic self-correction. Many LLMs, regardless of realizing what is critical to resolve complicated issues, fail to precisely retrieve or apply it when required, leading to incomplete or incorrect solutions. The rising significance of self-correction has led researchers to discover new strategies to reinforce LLMs’ efficiency and reliability in real-world purposes.
One of many principal challenges in enhancing LLMs is their incapability to appropriate their errors persistently. Whereas LLMs could generate appropriate responses in elements, they need assistance to revise incorrect solutions when confronted with errors. Present fashions both over-rely on prompt-based directions or fail to regulate their responses dynamically when errors come up. This difficulty is very pronounced in duties requiring multi-step reasoning, the place the mannequin’s incapability to revisit and revise earlier steps results in cumulative inaccuracies. To handle this downside, researchers are exploring methods that improve the mannequin’s capacity to independently detect and proper its errors, considerably enhancing efficiency in duties that contain reasoning and problem-solving.
Varied strategies have been developed to sort out this difficulty, however most have important limitations. Many depend on supervised fine-tuning, the place LLMs are educated to observe correction patterns from earlier responses. This strategy, nevertheless, typically amplifies biases from the unique coaching information, main the mannequin to make minimal or ineffective corrections. Different methods, resembling utilizing a number of fashions, make use of separate verifier fashions to information corrections. These strategies are computationally costly and is probably not possible for widespread deployment. Additionally, they undergo from a mismatch between the coaching information and real-world question distribution, resulting in suboptimal outcomes when utilized in follow. The necessity for a way enabling LLMs to self-correct with out exterior supervision has turn into more and more clear.
Researchers at Google DeepMind launched a novel strategy referred to as Self-Correction by way of Reinforcement Studying (SCoRe). This methodology goals to show LLMs to enhance their responses utilizing self-generated information, eliminating the necessity for exterior supervision or verifier fashions. By using multi-turn reinforcement studying (RL), SCoRe permits the mannequin to study from its responses and modify them in subsequent iterations. This methodology reduces the reliance on exterior information and trains the mannequin to deal with real-world duties extra successfully by enhancing the self-correction functionality. Utilizing this strategy, the researchers addressed the widespread downside of distribution mismatch in coaching information, making the mannequin’s corrections extra strong and efficient.
SCoRe’s methodology includes two key levels. The mannequin undergoes initialization coaching within the first stage and is optimized to generate an preliminary correction technique. This step helps the mannequin develop the power to make substantial corrections with out collapsing into minor edits. Within the second stage, reinforcement studying is employed to amplify the mannequin’s self-correction capacity. This stage focuses on enhancing the mannequin’s efficiency in a multi-turn setting, the place it’s rewarded for producing higher corrections on subsequent makes an attempt. Together with reward shaping within the reinforcement studying course of ensures that the mannequin focuses on enhancing accuracy relatively than making minimal adjustments. Combining these two levels considerably improves the mannequin’s capability to establish and proper errors, even when confronted with complicated queries.
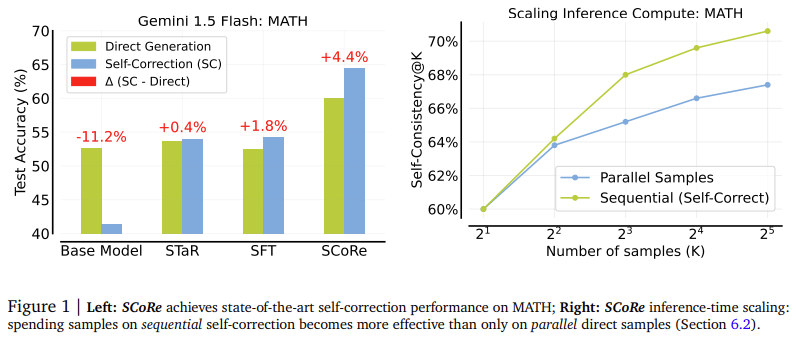
The outcomes of the SCoRe methodology exhibit a big enchancment within the self-correction efficiency of LLMs. When utilized to the Gemini 1.0 Professional and 1.5 Flash fashions, SCoRe achieved a 15.6% enchancment in self-correction accuracy for mathematical reasoning duties from the MATH dataset and a 9.1% enchancment for coding duties within the HumanEval dataset. These positive aspects spotlight the strategy’s effectiveness in comparison with conventional supervised fine-tuning strategies. The mannequin’s accuracy elevated to 60.0% for the primary try and 64.4% for the second try, showcasing its capacity to revise its preliminary response successfully. These outcomes are a big leap ahead, as present fashions sometimes fail to attain constructive self-correction charges.

The efficiency metrics additionally underline SCoRe’s success in lowering the variety of appropriate solutions that had been modified to incorrect solutions within the second try, a typical difficulty in different self-correction strategies. The mannequin improved its correction charge from 4.6% to five.8% in mathematical reasoning duties whereas lowering incorrect-to-correct adjustments. The SCoRe confirmed related enhancements in coding duties, reaching a 12.2% self-correction delta on the HumanEval benchmark, underscoring its generalizability throughout completely different domains.

In conclusion, the event of SCoRe addresses a long-standing downside within the subject of enormous language fashions. Researchers have considerably superior in enabling LLMs to self-correct successfully by using reinforcement studying on self-generated information. SCoRe improves accuracy and enhances the mannequin’s capacity to deal with complicated, multi-step reasoning duties. This strategy marks a big shift from earlier strategies, which relied on exterior supervision and suffered from information mismatches. The 2-stage coaching course of and reward shaping present a sturdy framework for enhancing LLMs’ self-correction capabilities, making them extra dependable for sensible purposes.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication..
Don’t Neglect to affix our 50k+ ML SubReddit
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.









{kind=link}