
Massive language fashions (LLMs) have demonstrated outstanding in-context studying capabilities throughout numerous domains, together with translation, perform studying, and reinforcement studying. Nonetheless, the underlying mechanisms of those skills, significantly in reinforcement studying (RL), stay poorly understood. Researchers try to unravel how LLMs study to generate actions that maximize future discounted rewards by way of trial and error, given solely a scalar reward sign. The central problem lies in understanding how LLMs implement temporal distinction (TD) studying, a basic idea in RL that entails updating worth beliefs based mostly on the distinction between anticipated and precise rewards.
Earlier analysis has explored in-context studying from a mechanistic perspective, demonstrating that transformers can uncover current algorithms with out express steerage. Research have proven that transformers can implement numerous regression and reinforcement studying strategies in-context. Sparse autoencoders have been efficiently used to decompose language mannequin activations into interpretable options, figuring out each concrete and summary ideas. A number of research have investigated the mixing of reinforcement studying and language fashions to enhance efficiency in numerous duties. This analysis contributes to the sphere by specializing in understanding the mechanisms by way of which giant language fashions implement reinforcement studying, constructing upon the prevailing literature on in-context studying and mannequin interpretability.
Researchers from the Institute for Human-Centered AI, Helmholtz Computational Well being Heart and Max Planck Institute for Organic Cybernetics have employed sparse autoencoders (SAEs) to analyse the representations supporting in-context studying in RL settings. This strategy has confirmed profitable in constructing a mechanistic understanding of neural networks and their representations. Earlier research have utilized SAEs to varied facets of neural community evaluation, demonstrating their effectiveness in uncovering underlying mechanisms. By using SAEs to check in-context RL in Llama 3 70B, researchers goal to analyze and manipulate the mannequin’s studying processes systematically. This technique permits for figuring out representations just like TD errors and Q-values throughout a number of duties, offering insights into how LLMs implement RL algorithms by way of next-token prediction.
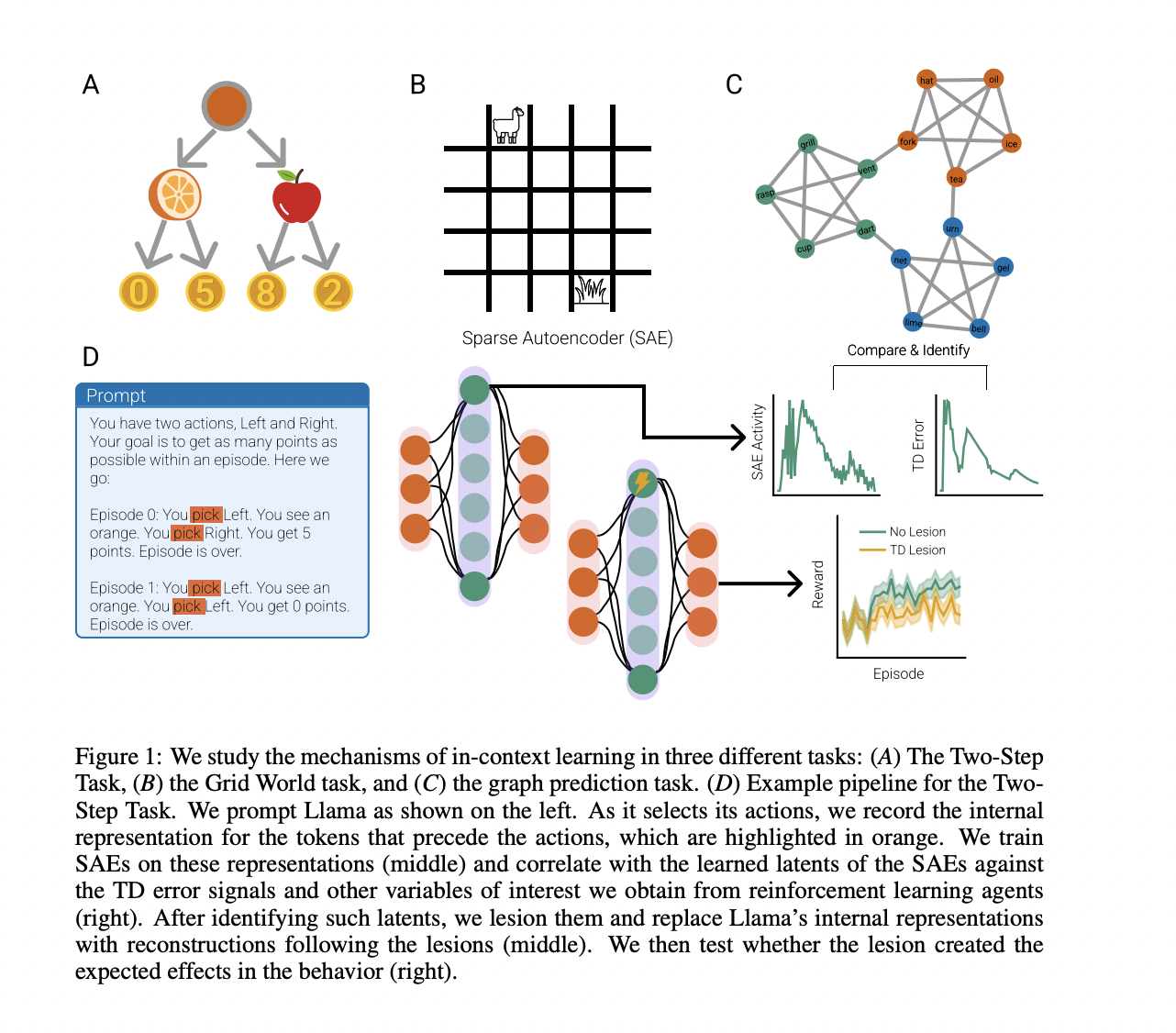
The researchers developed a strategy to investigate in-context reinforcement studying in Llama 3 70B utilizing SAEs. They designed a easy Markov Determination Course of impressed by the Two-Step Activity, the place Llama needed to make sequential decisions to maximise rewards. The mannequin’s efficiency was evaluated throughout 100 impartial experiments, every consisting of 30 episodes. SAEs have been skilled on residual stream outputs from Llama’s transformer blocks, utilizing variations of the Two-Step Activity to create a various coaching set. This strategy allowed the researchers to uncover representations just like TD errors and Q-values, offering insights into how Llama implements RL algorithms by way of next-token prediction.
The researchers prolonged their evaluation to a extra complicated 5×5 grid navigation process, the place Llama predicted the actions of Q-learning brokers. They discovered that Llama improved its motion predictions over time, particularly when supplied with right reward info. SAEs skilled on Llama’s residual stream representations revealed latents extremely correlated with Q-values and TD errors of the producing agent. Deactivating or clamping these TD latents considerably degraded Llama’s motion prediction capability and diminished correlations with Q-values and TD errors. These findings additional assist the speculation that Llama’s inside representations encode reinforcement learning-like computations, even in additional complicated environments with bigger state and motion areas.
Researchers examine Llama’s capability to study graph buildings with out rewards, utilizing an idea known as Successor Illustration (SR). They prompted Llama with observations from a random stroll on a latent group graph. Outcomes confirmed that Llama rapidly realized to foretell the subsequent state with excessive accuracy and developed representations just like the SR, capturing the graph’s international geometry. Sparse autoencoder evaluation revealed stronger correlations with SR and related TD errors than with model-based options. Deactivating key TD latents impaired Llama’s prediction accuracy and disrupted its realized graph representations, demonstrating the causal position of TD-like computations in Llama’s capability to study structural data.

This research supplies proof that enormous language fashions (LLMs) implement temporal distinction (TD) studying to unravel reinforcement studying issues in-context. By utilizing sparse autoencoders, researchers recognized and manipulated options essential for in-context studying, demonstrating their impression on LLM behaviour and representations. This strategy opens avenues for learning numerous in-context studying skills and establishes a connection between LLM studying mechanisms and people noticed in organic brokers, each of which implement TD computations in related eventualities.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our e-newsletter.. Don’t Neglect to hitch our 50k+ ML SubReddit
Thinking about selling your organization, product, service, or occasion to over 1 Million AI builders and researchers? Let’s collaborate!
Asjad is an intern guide at Marktechpost. He’s persuing B.Tech in mechanical engineering on the Indian Institute of Know-how, Kharagpur. Asjad is a Machine studying and deep studying fanatic who’s at all times researching the purposes of machine studying in healthcare.






{kind=link}