
Predibase pronounces the Predibase Inference Engine, their new infrastructure providing designed to be the perfect platform for serving fine-tuned small language fashions (SLMs). The Predibase Inference Engine dramatically improves SLM deployments by making them quicker, simply scalable, and cheaper for enterprises grappling with the complexities of productionizing AI. Constructed on Predibase’s improvements–Turbo LoRA and LoRA eXchange (LoRAX)–the Predibase Inference Engine is designed from the bottom as much as provide a best-in-class expertise for serving fine-tuned SLMs.
The necessity for such an innovation is evident. As AI turns into extra entrenched within the cloth of enterprise operations, the challenges related to deploying and scaling SLMs have grown more and more daunting. Homegrown infrastructure is usually ill-equipped to deal with the dynamic calls for of high-volume AI workloads, resulting in inflated prices, diminished efficiency, and operational bottlenecks. The Predibase Inference Engine addresses these challenges head-on, providing a tailored resolution for enterprise AI deployments.
Be part of Predibase webinar on October twenty ninth to be taught extra in regards to the Predibase Inference Engine!
The Key Challenges in Deploying LLMs at Scale
As companies proceed to combine AI into their core operations and have to show ROI, the demand for environment friendly, scalable options has skyrocketed. The deployment of LLMs, and fine-tuned SLMs specifically, has turn into a essential part of profitable AI initiatives however presents important challenges at scale:
- Efficiency Bottlenecks: Most cloud suppliers’ entry-level GPUs battle with manufacturing use circumstances, particularly these with spiky or variable workloads, leading to gradual response occasions and a diminished buyer expertise. Moreover, scaling LLM deployments to satisfy peak demand with out incurring prohibitive prices or efficiency degradation is a major problem because of the lack of GPU autoscaling capabilities in lots of cloud environments.
- Engineering Complexity: Adopting open-source fashions for manufacturing use requires enterprises to handle all the serving infrastructure themselves—a high-stakes, resource-intensive proposition. This provides important engineering complexity, demanding specialised experience and forcing groups to dedicate substantial sources to make sure dependable efficiency and scalability in manufacturing environments.
- Excessive Infrastructure Prices: Excessive-performing GPUs just like the NVIDIA H100 and A100 are in excessive demand and sometimes have restricted availability from cloud suppliers, resulting in potential shortages. These GPUs are usually supplied in “always-on” deployment fashions, which guarantee availability however may be expensive as a consequence of steady billing, no matter precise utilization.
These challenges underscore the necessity for an answer just like the Predibase Inference Engine, which is designed to streamline the deployment course of and supply a scalable, cost-effective infrastructure for managing SLMs.
Technical Breakthroughs within the Predibase Inference Engine
On the coronary heart of the Predibase Inference Engine are a set of modern options that collectively improve the deployment of SLMs:
- LoRAX: LoRA eXchange (LoRAX) permits for the serving of tons of of fine-tuned SLMs from a single GPU. This functionality considerably reduces infrastructure prices by minimizing the variety of GPUs wanted for deployment. It’s notably helpful for companies that have to deploy varied specialised fashions with out the overhead of dedicating a GPU to every mannequin. Study extra.
- Turbo LoRA: Turbo LoRA is our parameter-efficient fine-tuning methodology that accelerates throughput by 2-3 occasions whereas rivaling or exceeding GPT-4 by way of response high quality. These throughput enhancements enormously cut back inference prices and latency, even for high-volume use circumstances.
- FP8 Quantization: Implementing FP8 quantization can cut back the reminiscence footprint of deploying a fine-tuned SLM by 50%, main to just about 2x additional enhancements in throughput. This optimization not solely improves efficiency but additionally enhances the cost-efficiency of deployments, permitting for as much as 2x extra simultaneous requests on the identical variety of GPUs.
- GPU Autoscaling: Predibase SaaS deployments can dynamically alter GPU sources primarily based on real-time demand. This flexibility ensures that sources are effectively utilized, decreasing waste and value in periods of fluctuating demand.
These technical improvements are essential for enterprises trying to deploy AI options which can be each highly effective and economical. By addressing the core challenges related to conventional mannequin serving, the Predibase Inference Engine units a brand new customary for effectivity and scalability in AI deployments.
LoRA eXchange: Scale 100+ High quality-Tuned LLMs Effectively on a Single GPU
LoRAX is a cutting-edge serving infrastructure designed to deal with the challenges of deploying a number of fine-tuned SLMs effectively. In contrast to conventional strategies that require every fine-tuned mannequin to run on devoted GPU sources, LoRAX permits organizations to serve tons of of fine-tuned SLMs on a single GPU, drastically decreasing prices. By using dynamic adapter loading, tiered weight caching, and multi-adapter batching, LoRAX optimizes GPU reminiscence utilization and maintains excessive throughput for concurrent requests. This modern infrastructure allows cost-effective deployment of fine-tuned SLMs, making it simpler for enterprises to scale AI fashions specialised to their distinctive duties.
Get extra out of your GPU: 4x pace enhancements for SLMs with Turbo LoRA and FP8
Optimizing SLM inference is essential for scaling AI deployments, and two key strategies are driving main throughput efficiency good points. Turbo LoRA boosts throughput by 2-3x by way of speculative decoding, making it attainable to foretell a number of tokens in a single step with out sacrificing output high quality. Moreover, FP8 quantization additional will increase GPU throughput, enabling a lot more economical deployments when utilizing fashionable {hardware} like NVIDIA L40S GPUs.
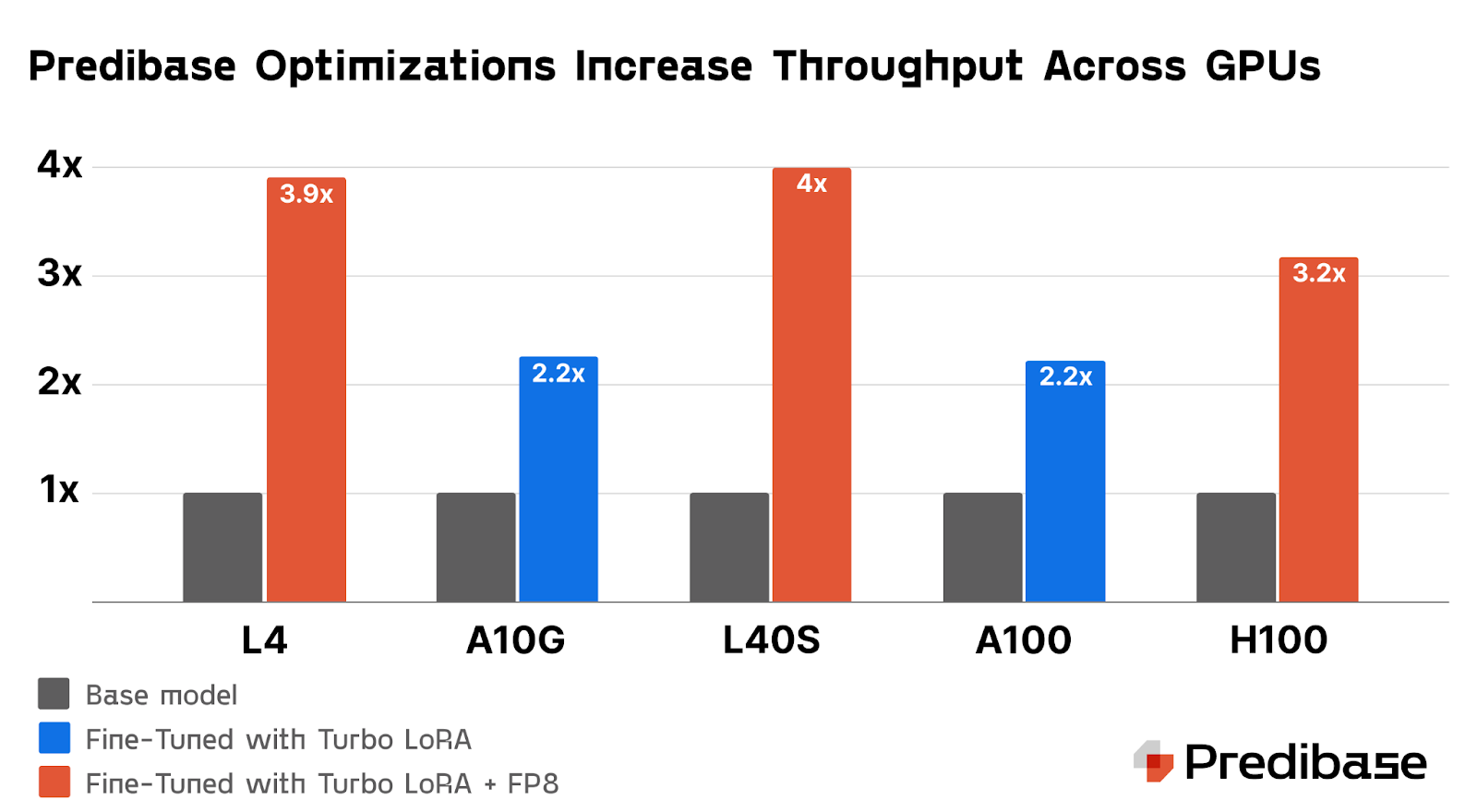
Turbo LoRA Will increase Throughput by 2-3x
Turbo LoRA combines Low Rank Adaptation (LoRA) and speculative decoding to boost the efficiency of SLM inference. LoRA improves response high quality by including new parameters tailor-made to particular duties, but it surely usually slows down token technology because of the further computational steps. Turbo LoRA addresses this by enabling the mannequin to foretell a number of tokens in a single step, considerably rising throughput by 2-3 occasions in comparison with base fashions with out compromising output high quality.
Turbo LoRA is especially efficient as a result of it adapts to all sorts of GPUs, together with high-performing fashions like H100s and entry degree fashions just like the A10g. This common compatibility ensures that organizations can deploy Turbo LoRA throughout completely different {hardware} setups (whether or not in Predibase’s cloud or their VPC setting) with no need particular changes for every GPU sort. This makes Turbo LoRA an economical resolution for enhancing the efficiency of SLMs throughout a variety of computing environments.
As well as, Turbo LoRA achieves these advantages all by way of a single mannequin whereas nearly all of speculative decoding implementations use a draft mannequin along with their major mannequin. This additional reduces the GPU necessities and community overhead.
Additional Enhance Throughput with FP8
FP8 quantization is a way that reduces the precision of a mannequin’s knowledge format from an ordinary floating-point illustration, comparable to FP16, to an 8-bit floating-point format. This compression reduces the mannequin’s reminiscence footprint by as much as 50%, permitting it to course of knowledge extra effectively and rising throughput on GPUs. The smaller dimension implies that much less reminiscence is required to retailer weights and carry out matrix multiplications, which consequently can almost double the throughput of a given GPU.
Past simply efficiency enhancements, FP8 quantization additionally impacts the cost-efficiency of deploying SLMs. By rising the variety of concurrent requests a GPU can deal with, organizations can meet their efficiency SLAs with fewer compute sources. Whereas solely the newest technology of NVIDIA GPUs assist FP8, making use of FP8 to L40S GPUs–now extra available in Amazon EC2–will increase throughput to outperform an A100 GPU whereas costing roughly 33% much less.
Optimized GPU Scaling for Efficiency and Value Effectivity
GPU autoscaling is a essential characteristic for managing AI workloads, making certain that sources are dynamically adjusted primarily based on real-time demand. Our Inference Engine’s capability to scale GPU sources as wanted helps enterprises optimize utilization, decreasing prices by solely scaling up when demand will increase and cutting down throughout quieter durations. This flexibility permits organizations to keep up high-performance AI operations with out over-provisioning sources.

For purposes that require constant efficiency, our platform provides the choice to order GPU capability, guaranteeing availability throughout peak masses. That is notably worthwhile to be used circumstances the place response occasions are essential, making certain that even throughout visitors spikes, AI fashions carry out with out interruptions or delays. Reserved capability ensures enterprises meet their efficiency SLAs with out pointless over-allocation of sources.
Moreover, the Inference Engine minimizes chilly begin occasions by quickly scaling sources, decreasing delays in startup and making certain fast changes to sudden will increase in visitors. This characteristic enhances the responsiveness of the system, permitting organizations to deal with unpredictable visitors surges effectively and with out compromising on efficiency.

Along with optimizing efficiency, GPU autoscaling considerably reduces deployment prices. In contrast to conventional “always-on” GPU deployments, which incur steady bills no matter precise utilization, autoscaling ensures sources are allotted solely when wanted. Within the instance above, an ordinary always-on deployment for an enterprise workload would price over $213,000 per 12 months, whereas an autoscaling deployment reduces that to lower than $155,000 yearly—providing a financial savings of almost 30%. (It’s vital to notice that each deployment configurations price lower than half as a lot as utilizing fine-tuned GPT-4o-mini.) By dynamically adjusting GPU sources primarily based on real-time demand, enterprises can obtain excessive efficiency with out the burden of overpaying for idle infrastructure, making AI deployments far cheaper.
Enterprise readiness
Designing AI infrastructure for enterprise purposes is advanced, with many essential particulars to handle should you’re constructing your personal. From safety compliance to making sure excessive availability throughout areas, enterprise-scale deployments require cautious planning. Groups should stability efficiency, scalability, and cost-efficiency whereas integrating with present IT techniques.
Predibase’s Inference Engine simplifies this by providing enterprise-ready options that handle these challenges, together with VPC integration, multi-region excessive availability, and real-time deployment insights. These options assist enterprises like Convirza deploy and handle AI workloads at scale with out the operational burden of constructing and sustaining infrastructure themselves.
“At Convirza, our workload may be extraordinarily variable, with spikes that require scaling as much as double-digit A100 GPUs to keep up efficiency. The Predibase Inference Engine and LoRAX enable us to effectively serve 60 adapters whereas persistently attaining a median response time of beneath two seconds,” stated Giuseppe Romagnuolo, VP of AI at Convirza. “Predibase offers the reliability we’d like for these high-volume workloads. The considered constructing and sustaining this infrastructure on our personal is daunting—fortunately, with Predibase, we don’t need to.”
Our cloud or yours: Digital Non-public Clouds
The Predibase Inference Engine is offered in our cloud or yours. Enterprises can select between deploying inside their very own personal cloud infrastructure or using Predibase’s totally managed SaaS platform. This flexibility ensures seamless integration with present enterprise IT insurance policies, safety protocols, and compliance necessities. Whether or not firms favor to maintain their knowledge and fashions fully inside their Digital Non-public Cloud (VPC) for enhanced safety and to make the most of cloud supplier spend commitments or leverage Predibase’s SaaS for added flexibility, the platform adapts to satisfy numerous enterprise wants.
Multi-Area Excessive Availability
The Inference Engine’s multi-region deployment characteristic ensures that enterprises can preserve uninterrupted service, even within the occasion of regional outages or disruptions. Within the occasion of a disruption, the platform robotically reroutes visitors to a functioning area and spins up extra GPUs to deal with the elevated demand. This fast scaling of sources minimizes downtime and ensures that enterprises can preserve their service-level agreements (SLAs) with out compromising efficiency or reliability.

By dynamically provisioning further GPUs within the failover area, the Inference Engine offers speedy capability to assist essential AI workloads, permitting companies to proceed working easily even within the face of surprising failures. This mixture of multi-region redundancy and autoscaling ensures that enterprises can ship constant, high-performance providers to their customers, irrespective of the circumstances.
Maximizing Effectivity with Actual-Time Deployment Insights
Along with the Inference Engine’s highly effective autoscaling and multi-region capabilities, Predibase’s Deployment Well being Analytics present important real-time insights for monitoring and optimizing your deployments. This instrument tracks essential metrics like request quantity, throughput, GPU utilization, and queue period, supplying you with a complete view of how effectively your infrastructure is performing. Through the use of these insights, enterprises can simply stability efficiency with price effectivity, scaling GPU sources up or down as wanted to satisfy fluctuating demand whereas avoiding over-provisioning.

With customizable autoscaling thresholds, Deployment Well being Analytics permits you to fine-tune your technique primarily based on particular operational wants. Whether or not it’s making certain that GPUs are effectively utilized throughout visitors spikes or cutting down sources to reduce prices, these analytics empower companies to keep up high-performance deployments that run easily always. For extra particulars on optimizing your deployment technique, try the full weblog publish.
Why Select Predibase?
Predibase is the main platform for enterprises serving fine-tuned LLMs, providing unmatched infrastructure designed to satisfy the particular wants of contemporary AI workloads. Our Inference Engine is constructed for max efficiency, scalability, and safety, making certain enterprises can deploy fine-tuned fashions with confidence. With built-in compliance and a concentrate on cost-effective, dependable mannequin serving, Predibase is the best choice for firms trying to serve fine-tuned LLMs at scale whereas sustaining enterprise-grade safety and effectivity.
Should you’re able to take your LLM deployments to the following degree, go to Predibase.com to be taught extra in regards to the Predibase Inference Engine, or attempt it at no cost to see firsthand how our options can remodel your AI operations.
Because of the Predibase group for the thought management/ Sources for this text. The Predibase AI group has supported us on this content material/article.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.









{kind=link}