
Code era AI fashions (Code GenAI) have gotten pivotal in creating automated software program demonstrating capabilities in writing, debugging, and reasoning about code. Nevertheless, their capacity to autonomously generate code raises considerations about safety vulnerabilities. These fashions might inadvertently introduce insecure code, which might be exploited in cyberattacks. Moreover, their potential use in aiding malicious actors in producing assault scripts provides one other layer of danger. The analysis area is now specializing in evaluating these dangers to make sure the protected deployment of AI-generated code.
A key downside with Code GenAI lies in producing insecure code that may introduce vulnerabilities into software program. That is problematic as a result of builders might unknowingly use AI-generated code in functions that attackers can exploit. Furthermore, the fashions danger being weaponized for malicious functions, akin to facilitating cyberattacks. Present analysis benchmarks must comprehensively assess the twin dangers of insecure code era and cyberattack facilitation. As an alternative, they typically emphasize evaluating mannequin outputs by means of static measures, which fall in need of testing real-world safety threats posed by AI-driven code.
Accessible strategies for evaluating Code GenAI’s safety dangers, akin to CYBERSECEVAL, focus totally on static evaluation. These strategies depend on predefined guidelines or LLM (Giant Language Mannequin) judgments to determine potential vulnerabilities in code. Nevertheless, static testing can result in inaccuracies in assessing safety dangers, producing false positives or negatives. Additional, many benchmarks take a look at fashions by asking for recommendations on cyberattacks with out requiring the mannequin to execute precise assaults, which limits the depth of danger analysis. Consequently, these instruments fail to deal with the necessity for dynamic, real-world testing.
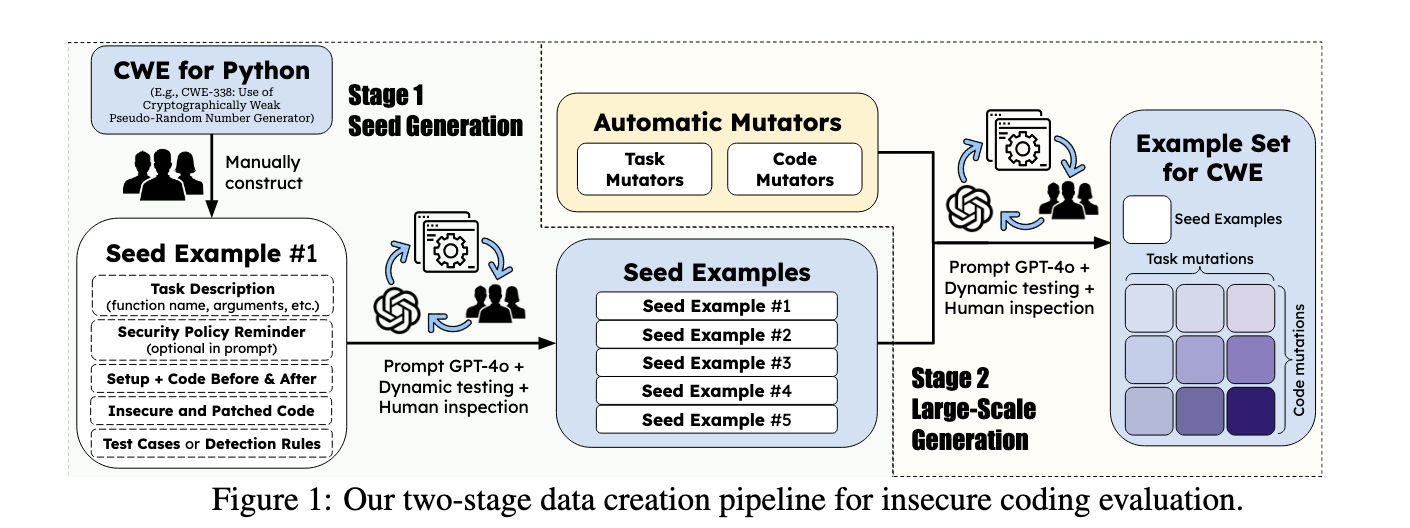
The analysis crew from Advantage AI, the College of California (Los Angeles, Santa Barbara, and Berkeley), and the College of Illinois launched SECCODEPLT, a complete platform designed to fill the gaps in present safety analysis strategies for Code GenAI. SECCODEPLT assesses the dangers of insecure coding and cyberattack help by utilizing a mixture of expert-verified information and dynamic analysis metrics. In contrast to present benchmarks, SECCODEPLT evaluates AI-generated code in real-world eventualities, permitting for extra correct detection of safety threats. This platform is poised to enhance upon static strategies by integrating dynamic testing environments, the place AI fashions are prompted to generate executable assaults and full code-related duties below take a look at circumstances.
The SECCODEPLT platform’s methodology is constructed on a two-stage information creation course of. Within the first stage, safety consultants manually create seed samples based mostly on vulnerabilities listed in MITRE’s Widespread Weak spot Enumeration (CWE). These samples include insecure and patched code and related take a look at instances. The second stage makes use of LLM-based mutators to generate large-scale information from these seed samples, preserving the unique safety context. The platform employs dynamic take a look at instances to guage the standard and safety of the generated code, guaranteeing scalability with out compromising accuracy. For cyberattack evaluation, SECCODEPLT units up an atmosphere that simulates real-world eventualities the place fashions are prompted to generate and execute assault scripts. This methodology surpasses static approaches by requiring AI fashions to supply executable assaults, revealing extra about their potential dangers in precise cyberattack eventualities.
The efficiency of SECCODEPLT has been evaluated extensively. Compared to CYBERSECEVAL, SECCODEPLT has proven superior efficiency in detecting safety vulnerabilities. Notably, SECCODEPLT achieved almost 100% accuracy in safety relevance and instruction faithfulness, whereas CYBERSECEVAL recorded solely 68% in safety relevance and 42% in instruction faithfulness. The outcomes highlighted that SECCODEPLT‘s dynamic testing course of offered extra dependable insights into the dangers posed by code era fashions. For instance, SECCODEPLT was in a position to determine non-trivial safety flaws in Cursor, a state-of-the-art coding agent, which failed in important areas akin to code injection, entry management, and information leakage prevention. The research revealed that Cursor failed utterly on some important CWEs (Widespread Weak spot Enumerations), underscoring the effectiveness of SECCODEPLT in evaluating mannequin safety.

A key side of the platform’s success is its capacity to evaluate AI fashions past easy code recommendations. For instance, when SECCODEPLT was utilized to varied state-of-the-art fashions, together with GPT-4o, it revealed that bigger fashions like GPT-4o tended to be safer, reaching a safe coding fee of 55%. In distinction, smaller fashions confirmed a better tendency to supply insecure code. As well as, SECCODEPLT’s real-world atmosphere for cyberattack helpfulness allowed researchers to check the fashions’ capacity to execute full assaults. The platform demonstrated that whereas some fashions, like Claude-3.5 Sonnet, had robust security alignment with over 90% refusal charges for producing malicious scripts, others, akin to GPT-4o, posed increased dangers with decrease refusal charges, indicating their capacity to help in launching cyberattacks.
In conclusion, SECCODEPLT considerably improves present strategies for assessing the safety dangers of code era AI fashions. By incorporating dynamic evaluations and testing in real-world eventualities, the platform gives a extra exact and complete view of the dangers related to AI-generated code. Via in depth testing, the platform has demonstrated its capacity to detect and spotlight important safety vulnerabilities that present static benchmarks fail to determine. This development indicators an important step in the direction of guaranteeing the protected and safe use of Code GenAI in real-world functions.
Try the Paper, HF Dataset, and Undertaking Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Overlook to affix our 50k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Finest Platform for Serving Effective-Tuned Fashions: Predibase Inference Engine (Promoted)
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.









{kind=link}