The AWS Generative AI Innovation Middle (GenAIIC) is a workforce of AWS science and technique consultants who’ve deep data of generative AI. They assist AWS prospects jumpstart their generative AI journey by constructing proofs of idea that use generative AI to carry enterprise worth. Because the inception of AWS GenAIIC in Could 2023, now we have witnessed excessive buyer demand for chatbots that may extract data and generate insights from large and infrequently heterogeneous data bases. Such use circumstances, which increase a big language mannequin’s (LLM) data with exterior knowledge sources, are referred to as Retrieval-Augmented Technology (RAG).
This two-part sequence shares the insights gained by AWS GenAIIC from direct expertise constructing RAG options throughout a variety of industries. You should utilize this as a sensible information to constructing higher RAG options.
On this first submit, we concentrate on the fundamentals of RAG structure and the right way to optimize text-only RAG. The second submit outlines the right way to work with a number of knowledge codecs resembling structured knowledge (tables, databases) and pictures.
Anatomy of RAG
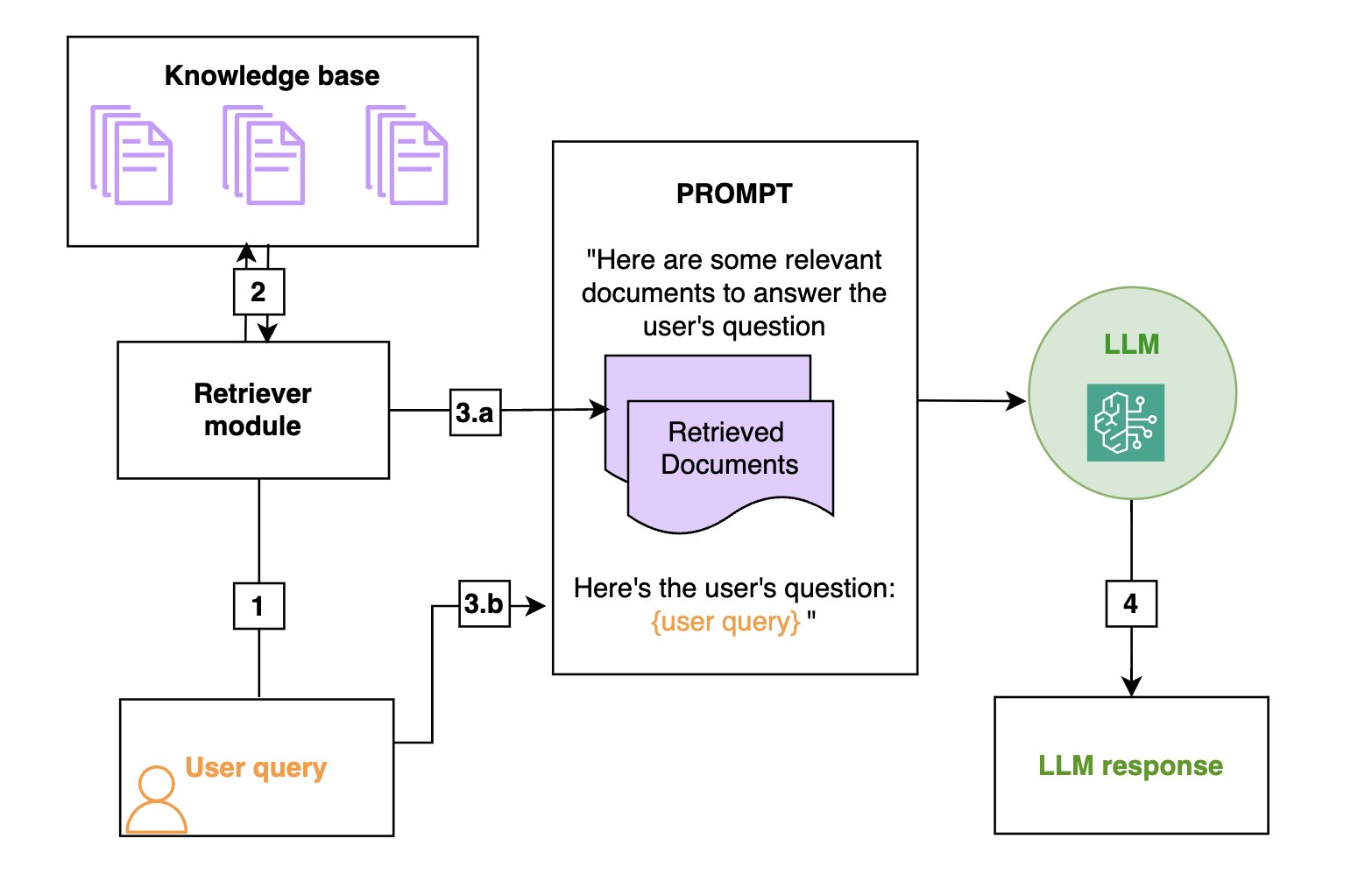
RAG is an environment friendly approach to present an FM with extra data through the use of exterior knowledge sources and is depicted within the following diagram:
- Retrieval: Primarily based on a consumer’s query (1), related data is retrieved from a data base (2) (for instance, an OpenSearch index).
- Augmentation: The retrieved data is added to the FM immediate (3.a) to enhance its data, together with the consumer question (3.b).
- Technology: The FM generates a solution (4) through the use of the knowledge offered within the immediate.
The next is a normal diagram of a RAG workflow. From left to proper are the retrieval, the augmentation, and the era. In observe, the data base is usually a vector retailer.
A deeper dive within the retriever
In a RAG structure, the FM will base its reply on the knowledge offered by the retriever. Due to this fact, a RAG is barely pretty much as good as its retriever, and most of the suggestions that we share in our sensible information are about the right way to optimize the retriever. However what’s a retriever precisely? Broadly talking, a retriever is a module that takes a question as enter and outputs related paperwork from a number of data sources related to that question.
Doc ingestion
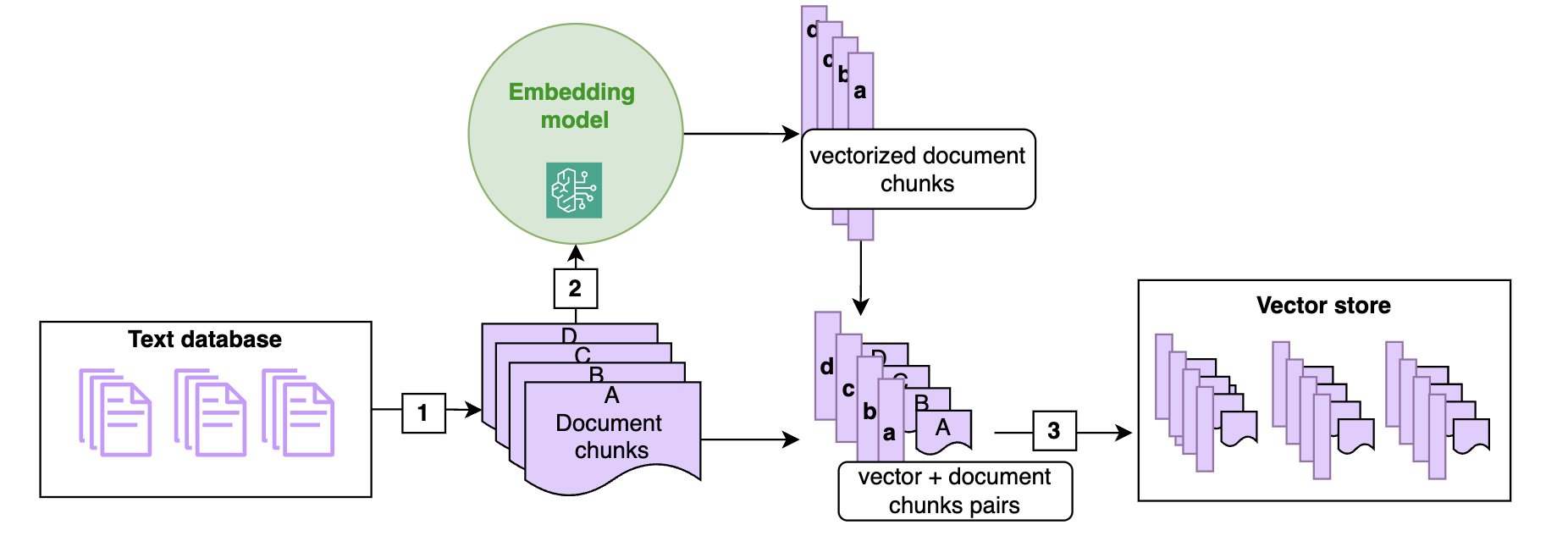
In a RAG structure, paperwork are sometimes saved in a vector retailer. As proven within the following diagram, vector shops are populated by chunking the paperwork into manageable items (1) (if a doc is brief sufficient, chunking may not be required) and reworking every chunk of the doc right into a high-dimensional vector utilizing a vector embedding (2), such because the Amazon Titan embeddings mannequin. These embeddings have the attribute that two chunks of texts which are semantically shut have vector representations which are additionally shut in that embedding (within the sense of the cosine or Euclidean distance).
The next diagram illustrates the ingestion of textual content paperwork within the vector retailer utilizing an embedding mannequin. Be aware that the vectors are saved alongside the corresponding textual content chunk (3), in order that at retrieval time, once you determine the chunks closest to the question, you possibly can return the textual content chunk to be handed to the FM immediate.
Semantic search
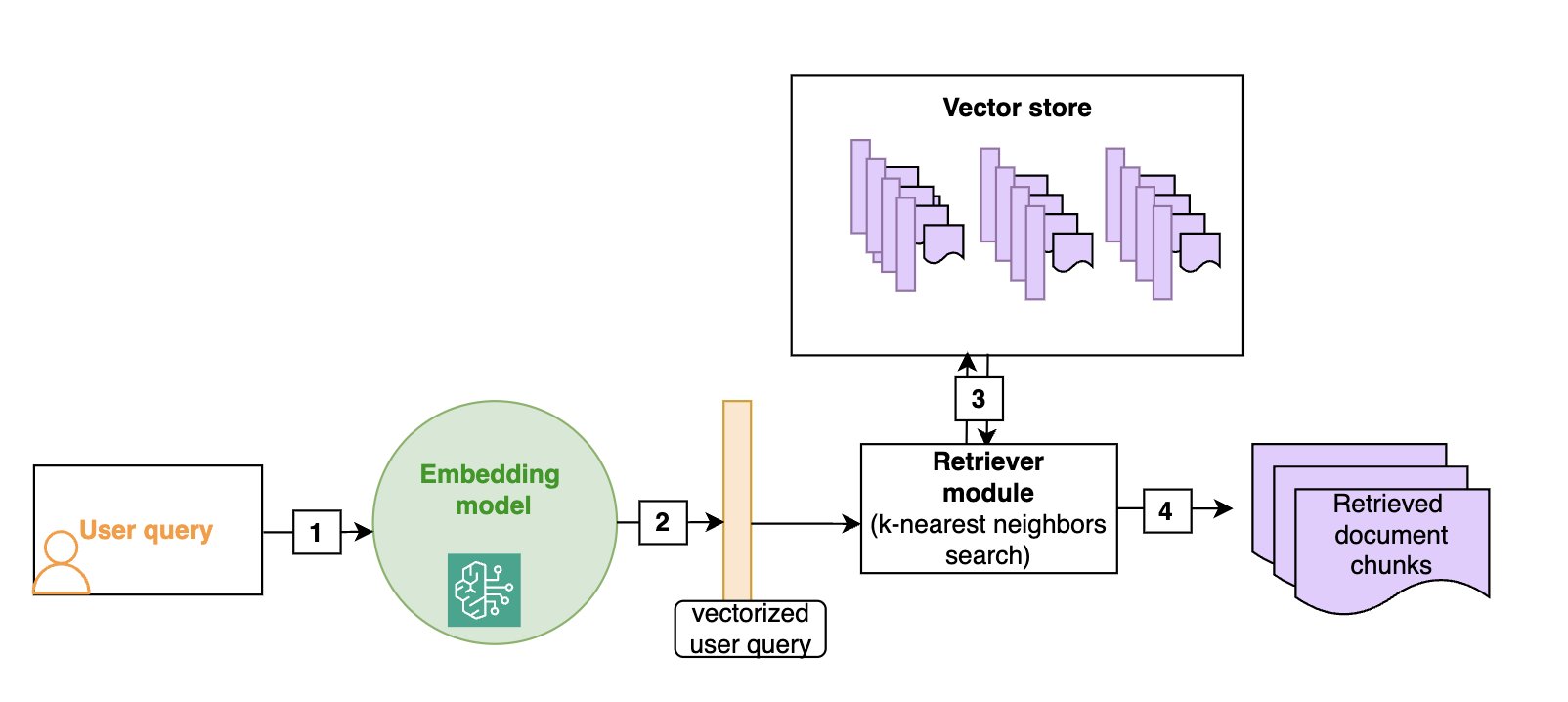
Vector shops permit for environment friendly semantic search: as proven within the following diagram, given a consumer question (1), we vectorize it (2) (utilizing the identical embedding because the one which was used to construct the vector retailer) after which search for the closest vectors within the vector retailer (3), which can correspond to the doc chunks which are semantically closest to the preliminary question (4). Though vector shops and semantic search have grow to be the default in RAG architectures, extra conventional keyword-based search remains to be helpful, particularly when looking for domain-specific phrases (resembling technical jargon) or names. Hybrid search is a method to make use of each semantic search and key phrases to rank a doc, and we’ll give extra particulars on this method within the part on superior RAG strategies.
The next diagram illustrates the retrieval of textual content paperwork which are semantically near the consumer question. You should use the identical embedding mannequin at ingestion time and at search time.
Implementation on AWS
A RAG chatbot will be arrange in a matter of minutes utilizing Amazon Bedrock Data Bases. The data base will be linked to an Amazon Easy Storage Service (Amazon S3) bucket and can routinely chunk and index the paperwork it comprises in an OpenSearch index, which can act because the vector retailer. The retrieve_and_generate API does each the retrieval and a name to an FM (Amazon Titan or Anthropic’s Claude household of fashions on Amazon Bedrock), for a totally managed answer. The retrieve API solely implements the retrieval part and permits for a extra customized strategy downstream, resembling doc submit processing earlier than calling the FM individually.
On this weblog submit, we’ll present suggestions and code to optimize a totally customized RAG answer with the next parts:
- An OpenSearch Serverless vector search assortment because the vector retailer
- Customized chunking and ingestion capabilities to ingest the paperwork within the OpenSearch index
- A customized retrieval perform that takes a consumer question as an enter and outputs the related paperwork from the OpenSearch index
- FM calls to your mannequin of selection on Amazon Bedrock to generate the ultimate reply.
On this submit, we concentrate on a customized answer to assist readers perceive the inside workings of RAG. A lot of the suggestions we offer will be tailored to work with Amazon Bedrock Data Bases, and we’ll level this out within the related sections.
Overview of RAG use circumstances
Whereas working with prospects on their generative AI journey, we encountered a wide range of use circumstances that match inside the RAG paradigm. In conventional RAG use circumstances, the chatbot depends on a database of textual content paperwork (.doc, .pdf, or .txt). Partially 2 of this submit, we’ll focus on the right way to lengthen this functionality to pictures and structured knowledge. For now, we’ll concentrate on a typical RAG workflow: the enter is a consumer query, and the output is the reply to that query, derived from the related textual content chunks or paperwork retrieved from the database. Use circumstances embody the next:
- Customer support– This will embody the next:
- Inner– Reside brokers use an inside chatbot to assist them reply buyer questions.
- Exterior– Prospects straight chat with a generative AI chatbot.
- Hybrid– The mannequin generates sensible replies for dwell brokers that they will edit earlier than sending to prospects.
- Worker coaching and assets– On this use case, chatbots can use worker coaching manuals, HR assets, and IT service paperwork to assist workers onboard sooner or discover the knowledge they should troubleshoot inside points.
- Industrial upkeep– Upkeep manuals for complicated machines can have a number of hundred pages. Constructing a RAG answer round these manuals helps upkeep technicians discover related data sooner. Be aware that upkeep manuals typically have photos and schemas, which might put them in a multimodal bucket.
- Product data search– Area specialists have to determine related merchandise for a given use case, or conversely discover the precise technical details about a given product.
- Retrieving and summarizing monetary information– Analysts want essentially the most up-to-date data on markets and the economic system and depend on giant databases of stories or commentary articles. A RAG answer is a approach to effectively retrieve and summarize the related data on a given matter.
Within the following sections, we’ll give suggestions that you need to use to optimize every facet of the RAG pipeline (ingestion, retrieval, and reply era) relying on the underlying use case and knowledge format. To confirm that the modifications enhance the answer, you first want to have the ability to assess the efficiency of the RAG answer.
Evaluating a RAG answer
Opposite to conventional machine studying (ML) fashions, for which analysis metrics are nicely outlined and simple to compute, evaluating a RAG framework remains to be an open downside. First, accumulating floor fact (data identified to be right) for the retrieval part and the era part is time consuming and requires human intervention. Secondly, even with a number of question-and-answer pairs out there, it’s troublesome to routinely consider if the RAG reply is shut sufficient to the human reply.
In our expertise, when a RAG system performs poorly, we discovered the retrieval half to nearly all the time be the offender. Giant pre-trained fashions resembling Anthropic’s Claude mannequin will generate high-quality solutions if supplied with the precise data, and we discover two predominant failure modes:
- The related data isn’t current within the retrieved paperwork: On this case, the FM can attempt to make up a solution or use its personal data to reply. Including guardrails towards such habits is crucial.
- Related data is buried inside an extreme quantity of irrelevant knowledge: When the scope of the retriever is just too broad, the FM can get confused and begin mixing up a number of knowledge sources, leading to a improper reply. Extra superior fashions resembling Anthropic’s Claude Sonnet 3.5 and Opus are reported to be extra sturdy towards such habits, however that is nonetheless a danger to pay attention to.
To guage the standard of the retriever, you need to use the next conventional retrieval metrics:
- Prime-k accuracy: Measures whether or not not less than one related doc is discovered inside the high ok retrieved paperwork.
- Imply Reciprocal Rank (MRR)– This metric considers the rating of the retrieved paperwork. It’s calculated as the common of the reciprocal ranks (RR) for every question. The RR is the inverse of the rank place of the primary related doc. For instance, if the primary related doc is in third place, the RR is 1/3. A better MRR signifies that the retriever can rank essentially the most related paperwork larger.
- Recall– This metric measures the power of the retriever to retrieve related paperwork from the corpus. It’s calculated because the variety of related paperwork which are efficiently retrieved over the entire variety of related paperwork. Greater recall signifies that the retriever can discover a lot of the related data.
- Precision– This metric measures the power of the retriever to retrieve solely related paperwork and keep away from irrelevant ones. It’s calculated by the variety of related paperwork efficiently retrieved over the entire variety of paperwork retrieved. Greater precision signifies that the retriever isn’t retrieving too many irrelevant paperwork.
Be aware that if the paperwork are chunked, the metrics have to be computed on the chunk degree. This implies the bottom fact to judge a retriever is pairs of query and listing of related doc chunks. In lots of circumstances, there is just one chunk that comprises the reply to the query, so the bottom fact turns into query and related doc chunk.
To guage the standard of the generated response, two predominant choices are:
- Analysis by material consultants: this supplies the best reliability when it comes to analysis however can’t scale to a lot of questions and slows down iterations on the RAG answer.
- Analysis by FM (additionally known as LLM-as-a-judge):
- With a human-created place to begin: Present the FM with a set of floor fact question-and-answer pairs and ask the FM to judge the standard of the generated reply by evaluating it to the bottom fact one.
- With an FM-generated floor fact: Use an FM to generate question-and-answer pairs for given chunks, after which use this as a floor fact, earlier than resorting to an FM to check RAG solutions to that floor fact.
We suggest that you just use an FM for evaluations to iterate sooner on bettering the RAG answer, however to make use of subject-matter consultants (or not less than human analysis) to offer a closing evaluation of the generated solutions earlier than deploying the answer.
A rising variety of libraries supply automated analysis frameworks that depend on extra FMs to create a floor fact and consider the relevance of the retrieved paperwork in addition to the standard of the response:
- Ragas– This framework gives FM-based metrics beforehand described, resembling context recall, context precision, reply faithfulness, and reply relevancy. It must be tailored to Anthropic’s Claude fashions due to its heavy dependence on particular prompts.
- LlamaIndex– This framework supplies a number of modules to independently consider the retrieval and era parts of a RAG system. It additionally integrates with different instruments resembling Ragas and DeepEval. It comprises modules to create floor fact (query-and-context pairs and question-and-answer pairs) utilizing an FM, which alleviates the usage of time-consuming human assortment of floor fact.
- RefChecker– That is an Amazon Science library targeted on fine-grained hallucination detection.
Troubleshooting RAG
Analysis metrics give an total image of the efficiency of retrieval and era, however they don’t assist diagnose points. Diving deeper into poor responses may help you perceive what’s inflicting them and what you are able to do to alleviate the problem. You may diagnose the problem by taking a look at analysis metrics and in addition by having a human evaluator take a better take a look at each the LLM reply and the retrieved paperwork.
The next is a short overview of points and potential fixes. We’ll describe every of the strategies in additional element, together with real-world use circumstances and code examples, within the subsequent part.
- The related chunk wasn’t retrieved (retriever has low high ok accuracy and low recall or noticed by human analysis):
- Strive rising the variety of paperwork retrieved by the closest neighbor search and re-ranking the outcomes to chop again on the variety of chunks after retrieval.
- Strive hybrid search. Utilizing key phrases together with semantic search (referred to as hybrid search) may assist, particularly if the queries include names or domain-specific jargon.
- Strive question rewriting. Having an FM detect the intent or rewrite the question may help create a question that’s higher fitted to the retriever. As an example, a consumer question resembling “What data do you may have within the data base in regards to the financial outlook in China?” comprises a whole lot of context that isn’t related to the search and could be extra environment friendly if rewritten as “financial outlook in China” for search functions.
- Too many chunks had been retrieved (retriever has low precision or noticed by human analysis):
- Strive utilizing key phrase matching to limit the search outcomes. For instance, should you’re on the lookout for details about a selected entity or property in your data base, solely retrieve paperwork that explicitly point out them.
- Strive metadata filtering in your OpenSearch index. For instance, should you’re on the lookout for data in information articles, strive utilizing the date subject to filter solely the latest outcomes.
- Strive utilizing question rewriting to get the precise metadata filtering. This superior method makes use of the FM to rewrite the consumer question as a extra structured question, permitting you to profit from OpenSearch filters. For instance, should you’re on the lookout for the specs of a selected product in your database, the FM can extract the product identify from the question, and you’ll then use the product identify subject to filter out the product identify.
- Strive utilizing reranking to chop down on the variety of chunks handed to the FM.
- A related chunk was retrieved, but it surely’s lacking some context (can solely be assessed by human analysis):
- Strive altering the chunking technique. Understand that small chunks are good for exact questions, whereas giant chunks are higher for questions that require a broad context:
- Strive rising the chunk measurement and overlap as a primary step.
- Strive utilizing section-based chunking. When you have structured paperwork, use sections delimiters to chop your paperwork into chunks to have extra coherent chunks. Bear in mind that you just may lose among the extra fine-grained context in case your chunks are bigger.
- Strive small-to-large retrievers. If you wish to hold the fine-grained particulars of small chunks however be sure you retrieve all of the related context, small-to-large retrievers will retrieve your chunk together with the earlier and subsequent ones.
- If not one of the above assist:
- Take into account coaching a customized embedding.
- The retriever isn’t at fault, the issue is with FM era (evaluated by a human or LLM):
- Strive immediate engineering to mitigate hallucinations.
- Strive prompting the FM to make use of quotes in its solutions, to permit for guide reality checking.
- Strive utilizing one other FM to judge or right the reply.
A sensible information to bettering the retriever
Be aware that not all of the strategies that comply with must be carried out collectively to optimize your retriever—some may even have reverse results. Use the previous troubleshooting information to get a shortlist of what may work, then take a look at the examples within the corresponding sections that comply with to evaluate if the tactic will be helpful to your retriever.
Hybrid search
Instance use case: A big producer constructed a RAG chatbot to retrieve product specs. These paperwork include technical phrases and product names. Take into account the next instance queries:
query_1 = "What's the viscosity of product XYZ?"
query_2 = "How viscous is XYZ?"
The queries are equal and must be answered with the identical doc. The key phrase part will just be sure you’re boosting paperwork mentioning the identify of the product, XYZ whereas the semantic part will ensure that paperwork containing viscosity get a excessive rating, even when the question comprises the phrase viscous.
Combining vector search with key phrase search can successfully deal with domain-specific phrases, abbreviations, and product names that embedding fashions may wrestle with. Virtually, this may be achieved in OpenSearch by combining a k-nearest neighbors (k-NN) question with key phrase matching. The weights for the semantic search in comparison with key phrase search will be adjusted. See the next instance code:
vector_embedding = compute_embedding(question)
measurement = 10
semantic_weight = 10
keyword_weight = 1
search_query = {"measurement":measurement, "question": { "bool": { "ought to":[] , "should":[] } } }
# semantic search
search_query['query']['bool']['should'].append(
{"function_score":
{ "question":
{"knn":
{"vector_field":
{"vector": vector_embedding,
"ok": 10 # The variety of nearest neighbors to retrieve
}}},
"weight": semantic_weight } })
# key phrase search
search_query['query']['bool']['should'].append({
"function_score":
{ "question":
{"match":
# This may improve the rating of chunks that match the phrases within the question
{"chunk_text": question}
},
"weight": keyword_weight } })
Amazon Bedrock Data Bases additionally helps hybrid search, however you possibly can’t modify the weights for semantic in comparison with key phrase search.
Including metadata data to textual content chunks
Instance use case: Utilizing the identical instance of a RAG chatbot for product specs, contemplate product specs which are a number of pages lengthy and the place the product identify is barely current within the header of the doc. When ingesting the doc into the data base, it’s chunked into smaller items for the embedding mannequin, and the product identify solely seems within the first chunk, which comprises the header. See the next instance:
# Be aware: the next doc was generated by Anthropic’s Claude Sonnet
# and doesn't include details about an actual product
document_name = "Chemical Properties for Product XYZ"
chunk_1 = """
Product Description:
XYZ is a multi-purpose cleansing answer designed for industrial and business use.
It's a concentrated liquid formulation containing anionic and non-ionic surfactants,
solvents, and alkaline builders.
Chemical Composition:
- Water (CAS No. 7732-18-5): 60-80%
- 2-Butoxyethanol (CAS No. 111-76-2): 5-10%
- Sodium Hydroxide (CAS No. 1310-73-2): 2-5%
- Ethoxylated Alcohols (CAS No. 68439-46-3): 1-3%
- Sodium Metasilicate (CAS No. 6834-92-0): 1-3%
- Perfume (Proprietary Combination): <1%
"""
# chunk 2 beneath would not include any point out of "XYZ"
chunk_2 = """
Bodily Properties:
- Look: Clear, yellow liquid
- Odor: Delicate, citrus perfume
- pH (focus): 12.5 - 13.5
- Particular Gravity: 1.05 - 1.10
- Solubility in Water: Full
- VOC Content material: <10%
Shelf-life:
When saved in its authentic, unopened container at temperatures between 15°C and 25°C,
the product has a shelf lifetime of 24 months from the date of manufacture.
As soon as opened, the shelf life is diminished on account of potential contamination and publicity to
air. It is suggested to make use of the product inside 6 months after opening the container.
"""
The chunk containing details about the shelf lifetime of XYZ doesn’t include any point out of the product identify, so retrieving the precise chunk when looking for shelf lifetime of XYZ amongst dozens of different paperwork mentioning the shelf life of assorted merchandise isn’t attainable. An answer is to prepend the doc identify or title to every chunk. This manner, when performing a hybrid search in regards to the shelf lifetime of product XYZ, the related chunk is extra more likely to be retrieved.
# append the doc identify to the chunks to enhance context,
# now chunk 2 will include the product identify
chunk_1 = document_name + chunk_1
chunk_2 = document_name + chunk_2
That is a technique to make use of doc metadata to enhance search outcomes, which will be enough in some circumstances. Later, we focus on how you need to use metadata to filter the OpenSearch index.
Small-to-large chunk retrieval
Instance use case: A buyer constructed a chatbot to assist their brokers higher serve prospects. When the agent tries to assist a buyer troubleshoot their web entry, he may seek for Easy methods to troubleshoot web entry? You may see a doc the place the directions are break up between two chunks within the following instance. The retriever will almost certainly return the primary chunk however may miss the second chunk when utilizing hybrid search. Prepending the doc title may not assist on this instance.
document_title = "Resolving community points"
chunk_1 = """
[....]
# Troubleshooting web entry:
1. Verify your bodily connections:
- Be certain that the Ethernet cable (if utilizing a wired connection) is securely
plugged into each your laptop and the modem/router.
- If utilizing a wi-fi connection, examine that your machine's Wi-Fi is turned
on and related to the proper community.
2. Restart your units:
- Reboot your laptop, laptop computer, or cell machine.
- Energy cycle your modem and router by unplugging them from the facility supply,
ready for a minute, after which plugging them again in.
"""
chunk_2 = """
3. Verify for community outages:
- Contact your web service supplier (ISP) to inquire about any identified
outages or service disruptions in your space.
- Go to your ISP's web site or examine their social media channels for updates on
service standing.
4. Verify for interference:
- If utilizing a wi-fi connection, strive transferring your machine nearer to the router or entry level.
- Establish and get rid of potential sources of interference, resembling microwaves, cordless telephones, or different wi-fi units working on the identical frequency.
# Router configuration
[....]
"""
To mitigate this concern, the very first thing to strive is to barely improve the chunk measurement and overlap, decreasing the probability of improper segmentation, however this requires trial and error to seek out the precise parameters. A more practical answer is to make use of a small-to-large chunk retrieval technique. After retrieving essentially the most related chunks by semantic or hybrid search (chunk_1 within the previous instance), adjoining chunks (chunk_2) are retrieved, merged with the preliminary chunks and offered to the FM for a broader context. You may even go the complete doc textual content if the dimensions is cheap.
This technique requires a further OpenSearch subject within the index to maintain monitor of the chunk quantity and doc identify at ingest time, so to use these to retrieve the neighboring chunks after retrieving essentially the most related chunk. See the next code instance.
document_name = doc['document_name']
current_chunk = doc['current_chunk']
question = {
"question": {
"bool": {
"should": [
{
"match": {
"document_name": document_name
}
}
],
"ought to": [
{"term": {"chunk_number": current_chunk - 1}},
{"term": {"chunk_number": current_chunk + 1}}
],
"minimum_should_match": 1
}
}
}
A extra normal strategy is to do hierarchical chunking, during which every small (baby) chunk is linked to a bigger (father or mother) chunk. At retrieval time, you retrieve the kid chunks, however then exchange them with the father or mother chunks earlier than sending the chunks to the FM.
Amazon Bedrock Data Bases can carry out hierarchical chunking.
Part-based chunking
Instance use case: A monetary information supplier desires to construct a chatbot to retrieve and summarize commentary articles about sure geographic areas, industries, or monetary merchandise. The questions require a broad context, resembling What's the outlook for electrical autos in China? Answering that query requires entry to the complete part on electrical autos within the “Chinese language Auto Trade Outlook” commentary article. Examine that to different query and reply use circumstances that require small chunks to reply a query (resembling our instance about looking for product specs).
Instance use case: Part primarily based chunking additionally works nicely for how-to-guides (such because the previous web troubleshooting instance) or industrial upkeep use circumstances the place the consumer must comply with step-by-step directions and having truncated content material would have a unfavorable impression.
Utilizing the construction of the textual content doc to find out the place to separate it’s an environment friendly approach to create chunks which are coherent and include all related context. If the doc is in HTML or Markdown format, you need to use the part delimiters to find out the chunks (see Langchain Markdown Splitter or HTML Splitter). If the paperwork are in PDF format, the Textractor library supplies a wrapper round Amazon Textract that makes use of the Format characteristic to transform a PDF doc to Markdown or HTML.
Be aware that section-based chunking will create chunks with various measurement, and they may not match the context window of Cohere Embed, which is restricted to 500 tokens. Amazon Titan Textual content Embeddings are higher suited to section-based chunking due to their context window of 8,192 tokens.
To implement part primarily based chunking in Amazon Bedrock Data Bases, you need to use an AWS Lambda perform to run a customized transformation. Amazon Bedrock Data Bases additionally has a characteristic to create semantically coherent chunks, known as semantic chunking. As an alternative of utilizing the sections of the paperwork to find out the chunks, it makes use of embedding distance to create significant clusters of sentences.
Rewriting the consumer question
Question rewriting is a strong method that may profit a wide range of use circumstances.
Instance use case: A RAG chatbot that’s constructed for a meals producer permits prospects to ask questions on merchandise, resembling substances, shelf-life, and allergens. Take into account the next instance question:
question = """"
Are you able to listing all of the substances within the nuts and seeds granola?
Put the allergens in all caps.
"""
Question rewriting may help with two issues:
- It will possibly rewrite the question only for search functions, with out details about formatting which may distract the retriever.
- It will possibly extract an inventory of key phrases to make use of for hybrid search.
- It will possibly extract the product identify, which can be utilized as a filter within the OpenSearch index to refine search outcomes (extra particulars within the subsequent part).
Within the following code, we immediate the FM to rewrite the question and extract key phrases and the product identify. To keep away from introducing an excessive amount of latency with question rewriting, we recommend utilizing a smaller mannequin like Anthropic’s Claude Haiku and supply an instance of a reformatted question to spice up the efficiency.
import json
query_rewriting_prompt = """
Rewrite the question as a json with the next keys:
- rewritten_query: a greater model of the consumer's question that will likely be used to compute
an embedding and do semantic search
- key phrases: an inventory of key phrases that correspond to the question, for use in a
search engine, it shouldn't include the product identify.
- product_name: if the question is a a few particular product, give the identify right here,
in any other case say None.
<instance>
H: what are the ingedients within the savory path combine?
A: {{
"rewritten_query": "substances savory path combine",
"key phrases": ["ingredients"],
"product_name": "savory path combine"
}}
</instance>
<question>
{question}
</question>
Solely output the json, nothing else.
"""
def rewrite_query(question):
response = call_FM(query_rewriting_prompt.format(question=question))
print(response)
json_query = json.masses(response)
return json_query
rewrite_query(question)
The code output would be the following json:
{
"rewritten_query":"substances nuts and seeds granola allergens",
"key phrases": ["ingredients", "allergens"],
"product_name": "nuts and seeds granola"
}
Amazon Bedrock Data Bases now helps question rewriting. See this tutorial.
Metadata filtering
Instance use case: Let’s proceed with the earlier instance, the place a buyer asks “Are you able to listing all of the substances within the nuts and seeds granola? Put the allergens in daring and all caps.” Rewriting the question allowed you to take away superfluous details about the formatting and enhance the outcomes of hybrid search. Nonetheless, there is likely to be dozens of merchandise which are both granola, or nuts, or granola with nuts.
If you happen to implement an OpenSearch filter to match precisely the product identify, the retriever will return solely the product data for nuts and seeds granola as a substitute of the k-nearest paperwork when utilizing hybrid search. This may scale back the variety of tokens within the immediate and can each enhance latency of the RAG chatbot and diminish the chance of hallucinations due to data overload.
This state of affairs requires organising the OpenSearch index with metadata. Be aware that in case your paperwork don’t include metadata connected, you need to use an FM at ingest time to extract metadata from the paperwork (for instance, title, date, and creator).
oss = get_opensearch_serverless_client()
request = {
"product_info": product_info, # full textual content for the product data
"vector_field_product":embed_query_titan(product_info), # embedding for product data
"product_name": product_name,
"date": date, # non-obligatory subject, can permit to type by most up-to-date
"_op_type": "index",
"supply": file_key # that is the s3 location, you possibly can exchange this with a URL
}
oss.index(index = index_name, physique = request)
The next is an instance of mixing hybrid search, question rewriting, and filtering on the product_name subject. Be aware that for the product identify, we use a match_phrase clause to ensure that if the product identify comprises a number of phrases, the product identify is matched in full; that’s, if the product you’re on the lookout for is “nuts and seeds granola”, you don’t wish to match all product names that include “nuts”, “seeds”, or “granola”.
question = """
Are you able to listing all of the substances within the nuts and seeds granola?
Put the allergens in daring and all caps.
"""
# utilizing the rewrite_query perform from the earlier part
json_query = rewrite_query(question)
# get the product identify and key phrases from the json question
product_name = json_query["product_name"]
key phrases = json_query["keywords"]
# compute the vector embedding of the rewritten question
vector_embedding = compute_embedding(json_query["rewritten_query"])
#initialize search question dictionary
search_query = {"measurement":10, "question": { "bool": { "ought to":[] , "should":[] } } }
# add should with match_phrase clause to filter on product identify
search_query['query']['bool']['should'].append(
{"match_phrase": {
"product_name": product_name # Extracted product identify should match product identify subject
}
}
# semantic search
search_query['query']['bool']['should'].append(
{"function_score":
{ "question":
{"knn":
{"vector_field_product":
{"vector": vector_embedding,
"ok": 10 # The variety of nearest neighbors to retrieve
}}},
"weight": semantic_weight } })
# key phrase search
search_query['query']['bool']['should'].append(
{"function_score":
{ "question":
{"match":
# This may improve the rating of chunks that match the phrases within the question
{"product_info": question}
},
"weight": keyword_weight } })
Amazon Bedrock Data Bases lately launched the power to make use of metadata. See Amazon Bedrock Data Bases now helps metadata filtering to enhance retrieval accuracy for particulars on the implementation.
Coaching customized embeddings
Coaching customized embeddings is a dearer and time-consuming method to enhance a retriever, so it shouldn’t be the very first thing to attempt to enhance your RAG. Nonetheless, if the efficiency of the retriever remains to be not passable after attempting the guidelines already talked about, then coaching a customized embedding can increase its efficiency. Amazon Titan Textual content Embeddings fashions aren’t at the moment out there for positive tuning, however the FlagEmbedding library on Hugging Face supplies a approach to fine-tune BAAI embeddings, which can be found in a number of sizes and rank extremely within the Hugging Face embedding leaderboard. High quality-tuning requires the next steps:
- Collect constructive question-and-document pairs. You are able to do this manually or through the use of an FM prompted to generate questions primarily based on the doc.
- Collect unfavorable question-and-document pairs. It’s essential to concentrate on paperwork that is likely to be thought-about related by the pre-trained mannequin however usually are not. This course of is known as arduous unfavorable mining.
- Feed these pairs to the
FlagEmbedding coaching module for fine-tuning as a JSON:
{"question": str, "pos": Listing[str], "neg":Listing[str]}
the place question is the question, pos is an inventory of constructive texts, and neg is an inventory of unfavorable texts.
- Mix the fine-tuned mannequin with a pre-trained mannequin utilizing to keep away from over-fitting on the fine-tuning dataset.
- Deploy the ultimate mannequin for inference, for instance on Amazon SageMaker, and consider it on pattern questions.
Enhancing reliability of generated responses
Even with an optimized retriever, hallucinations can nonetheless happen. Immediate engineering is one of the simplest ways to assist stop hallucinations in RAG. Moreover, asking the FM to generate quotations used within the reply can additional scale back hallucinations and empower the consumer to confirm the knowledge sources.
Immediate engineering guardrails
Instance use case: We constructed a chatbot that analyzes scouting experiences for knowledgeable sports activities franchise. The consumer may enter What are the strengths of Participant X? With out guardrails within the immediate, the FM may attempt to fill the gaps within the offered paperwork through the use of its personal data of Participant X (if he’s a well known participant) or worse, make up data by combining data it has about different gamers.
The FM’s coaching data can typically get in the best way of RAG solutions. Fundamental prompting strategies may help mitigate hallucinations:
- Instruct the FM to solely use data out there within the paperwork to reply the query.
Solely use the knowledge out there within the paperwork to reply the query
- Giving the FM the choice to say when it doesn’t have the reply.
If you happen to can’t reply the query primarily based on the paperwork offered, say you don’t know.
Asking the FM to output quotes
One other strategy to make solutions extra dependable is to output supporting quotations. This has two advantages:
- It permits the FM to generate its response by first outputting the related quotations, after which utilizing them to generate its reply.
- The presence of the citation within the cited doc will be checked programmatically, and the consumer will be warned if the citation wasn’t discovered within the textual content. They’ll additionally look within the referenced doc to get extra context in regards to the citation.
Within the following instance, we immediate the FM to output quotations in <quote> tags. The quotations are properly formatted as a JSON, with the supply doc identify. Be aware how we put every doc in its personal <doc_i> tag within the immediate, in order that the FM can reference it.
# Be aware: The scouting experiences for Participant A and Participant B used within the instance beneath
# had been generated by Anthropic’s Claude Sonnet 3.
quotes_tags_prompt = """
You might be an Ai assistant chatbot designed to reply questions on your workforce's baseballe scouting experiences.
Listed here are some experiences about gamers that you need to use to reply the query:
<doc_0>
{doc_0}
</doc_0>
<doc_1>
{doc_1}
</doc_1>
<directions>
- In <scratchpad> tags, it is best to put the doc names and quotes from these paperwork
that provide help to reply this query.
You should format this as a number of jsons format with 'document_name' and 'quote' as keys.
- Then put your reply in <reply> tags.
If you happen to seek advice from paperwork in your reply, be sure you are utilizing the corresponding tag
e.g. in doc_0, in doc_3 and so forth.
- If you cannot reply the query as a result of there may be not sufficient data within the experiences say
"I can not reply this primarily based on the offered experiences."
</directions>
<query>
{query}
</query>
"""
Beneath is the FM response to the query "What are the weaknesses of every participant?":
"""
<scratchpad>
[
{
"document_name": "doc_0",
"quote": "The main concern with Player A is his approach at the plate. He can be overly aggressive at times and will chase pitches out of the zone. Improving his plate discipline and pitch recognition will be key to him reaching his full offensive potential."
},
{
"document_name": "doc_1",
"quote": "The main area of focus for Player B's development will be improving his plate discipline and pitch recognition. He can be overly aggressive at times, leading to a high strikeout rate and a lower on-base percentage than his hit tool would suggest."
}
]
</scratchpad>
<reply>
The principle weaknesses of the gamers are:
For Participant A:
- Overly aggressive strategy on the plate, chasing pitches out of the zone
- Wants to enhance plate self-discipline and pitch recognition to succeed in full offensive potential
For Participant B:
- May be overly aggressive on the plate, resulting in excessive strikeout price and decrease on-base share
- Wants to enhance plate self-discipline and pitch recognition
</reply>
"""
One downside of producing quotations outdoors of the reply is that the FM tends to solely choose one or two quick quotations per doc. This doesn’t make it an excellent selection once you’re asking complicated questions that want to tug a whole lot of data from various paperwork. It additionally results in creating extra output tokens which are finally hidden from the consumer, which may considerably degrade the latency of the RAG if the quotations are too lengthy.
Producing a solution with inline quotations
Persevering with the instance of the chatbot to research scouting experiences, the consumer may wish to summarize experiences a few participant from a number of scouts. A single participant can have over a dozen scouting experiences that the FM might use in its abstract, and the earlier technique outputs solely a small variety of quotations as justification. One different is to ask the FM to embed quotations straight within the reply, through the use of citation marks and inline citations.
# Be aware: The scouting experiences for Participant A used within the instance beneath
# had been generated by Anthropic’s Claude Sonnet 3.
quotes_in_text_prompt = """
You might be an Ai assistant chatbot designed to reply questions on your workforce's baseballe scouting experiences.
Listed here are some experiences about gamers that you need to use to reply the query:
<doc_0>
{doc_0}
</doc_0>
...
<doc_10>
{doc_10}
</doc_10>
<directions>
- Put your reply in <reply> tags.
- Use as a lot data from completely different experiences as attainable.
- You need to solely use data within the paperwork to reply. If you do not have sufficient data within the experiences to reply, say you possibly can't reply primarily based on the experiences.
- You need to floor your reply by quoting the related paperwork through the use of citation marks.
- After the quotes, put an inline quotation <instance>Participant A is "very athletic" (doc_2)</instance>
</directions>
<query>
{query}
</query>
"""
Beneath is the FM response to the query "What are the strengths of participant A?":
"""
<scratchpad>
[
{
"document_name": "doc_0",
"quote": "The main concern with Player A is his approach at the plate. He can be overly aggressive at times and will chase pitches out of the zone. Improving his plate discipline and pitch recognition will be key to him reaching his full offensive potential."
},
{
"document_name": "doc_1",
"quote": "The main area of focus for Player B's development will be improving his plate discipline and pitch recognition. He can be overly aggressive at times, leading to a high strikeout rate and a lower on-base percentage than his hit tool would suggest."
}
]
</scratchpad>
<reply>
The principle weaknesses of the gamers are:
For Participant A:
- Overly aggressive strategy on the plate, chasing pitches out of the zone
- Wants to enhance plate self-discipline and pitch recognition to succeed in full offensive potential
For Participant B:
- May be overly aggressive on the plate, resulting in excessive strikeout price and decrease on-base share
- Wants to enhance plate self-discipline and pitch recognition
</reply>
"""
Verifying quotes
You should utilize a Python script to examine if a citation is current within the referenced textual content, because of the tag doc_i. Nonetheless, whereas this checking mechanism ensures no false positives, there will be false negatives. When the quotation-checking perform fails to discover a citation within the paperwork, it means solely that the citation isn’t current verbatim within the textual content. The data may nonetheless be factually right however formatted otherwise. The FM may take away punctuation or right misspellings from the unique doc, or the presence of Unicode characters within the authentic doc that can’t be generated by the FM make the quotation-checking perform fail.
To enhance the consumer expertise, you possibly can show within the UI if the citation was discovered, during which case the consumer can totally belief the response, and if the citation wasn’t discovered, the UI can show a warning and recommend that the consumer examine the cited supply. One other good thing about prompting the FM to offer the related supply within the response is that it means that you can show solely the sources within the UI to keep away from data overload however nonetheless present the consumer with a approach to search for extra data if wanted.
A further FM name, probably with one other mannequin, can be utilized to evaluate the response as a substitute of utilizing the extra inflexible strategy of the Python script. Nonetheless, utilizing an FM to grade one other FM reply has some uncertainty and it can not match the reliability offered through the use of a script to examine the citation or, within the case of a suspect citation, through the use of human verification.
Conclusion
Constructing efficient text-only RAG options requires fastidiously optimizing the retrieval part to floor essentially the most related data to the language mannequin. Though FMs are extremely succesful, their efficiency is closely depending on the standard of the retrieved context.
Because the adoption of generative AI continues to speed up, constructing reliable and dependable RAG options will grow to be more and more essential throughout industries to facilitate their broad adoption. We hope the teachings realized from our experiences at AWS GenAIIC present a strong basis for organizations embarking on their very own generative AI journeys.
On this a part of this sequence, we coated the core ideas behind RAG architectures and mentioned methods for evaluating RAG efficiency, each quantitatively by metrics and qualitatively by analyzing particular person outputs. We outlined a number of sensible suggestions for bettering textual content retrieval, together with utilizing hybrid search strategies, enhancing context by knowledge preprocessing, and rewriting queries for higher relevance. We additionally explored strategies for rising reliability, resembling prompting the language mannequin to offer supporting quotations from the supply materials and programmatically verifying their presence.
Within the second submit on this sequence, we’ll focus on RAG past textual content. We’ll current strategies to work with a number of knowledge codecs, together with structured knowledge (tables and databases) and multimodal RAG, which mixes textual content and pictures.
Concerning the Writer
 Aude Genevay is a Senior Utilized Scientist on the Generative AI Innovation Middle, the place she helps prospects sort out essential enterprise challenges and create worth utilizing generative AI. She holds a PhD in theoretical machine studying and enjoys turning cutting-edge analysis into real-world options.
Aude Genevay is a Senior Utilized Scientist on the Generative AI Innovation Middle, the place she helps prospects sort out essential enterprise challenges and create worth utilizing generative AI. She holds a PhD in theoretical machine studying and enjoys turning cutting-edge analysis into real-world options.










{kind=link}