
The potential of multimodal giant language fashions (MLLMs) to allow complicated long-chain reasoning that comes with textual content and imaginative and prescient raises a fair higher barrier within the realm of synthetic intelligence. Whereas text-centric reasoning duties are being progressively superior, multimodal duties add extra challenges rooted within the lack of wealthy, complete reasoning datasets and environment friendly coaching methods. Presently, many fashions are likely to lack accuracy of their reasoning when uncovered to complicated knowledge involving photographs, which limits their utility to real-world purposes in techniques with autonomous exercise, medical diagnoses, or studying supplies.
Conventional strategies for enhancing reasoning capability rely largely on Chain-of-Thought (CoT) prompting or structured datasets. Nonetheless, these approaches have important drawbacks. Crafting annotated datasets for the duty of visible reasoning could be very resource-intensive and requires huge human assets. Reasoning and summarizing in a single step usually leads to badly fragmented or simply plain weird reasoning chains. Furthermore, with the shortage of datasets and the direct strategy to coaching these techniques, they can not generalize successfully throughout a wide range of duties. These constraints name for brand spanking new methodologies to be developed to amplify the reasoning functionality of multi-modal synthetic intelligence techniques.
Researchers from NTU, Tencent, Tsinghua College, and Nanjing College launched Perception-V to deal with these challenges via a singular mixture of scalable knowledge technology and a multi-agent framework. It affords an incremental methodology for producing diversified and coherent reasoning pathways via a multi-granularity methodology of pathway analysis to make sure the standard of the generated pathways. A definite multi-agent system decomposes duties into two specialised roles: the reasoning agent, which generates detailed logical steps, and the abstract agent, which validates and refines these outputs for accuracy. By leveraging Iterative Direct Choice Optimization (DPO), a reinforcement studying methodology, the system achieves alignment with human-like judgment. This collaborative structure permits important advances in reasoning accuracy and task-specific efficiency.
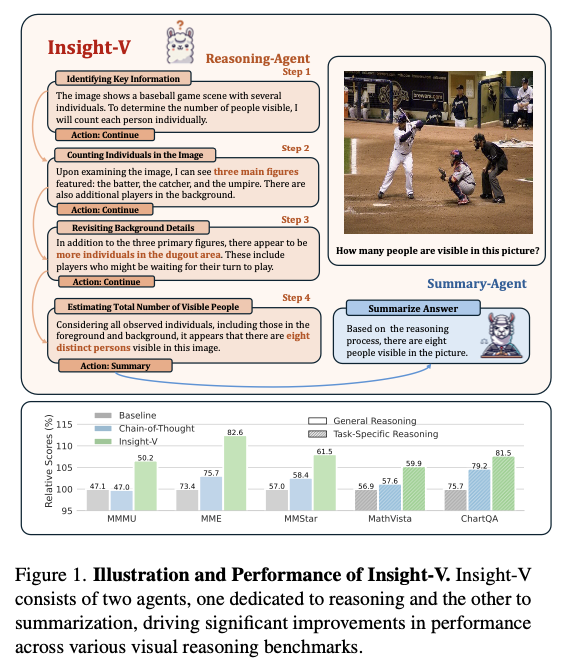
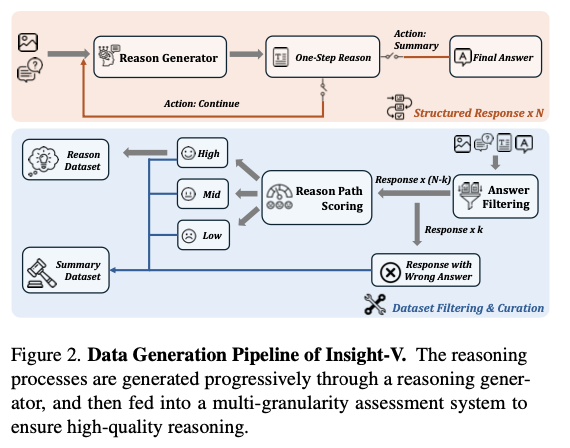
Perception-V has a structured dataset of greater than 200K reasoning samples and over 1.2 million summarization examples obtained from associated benchmarks corresponding to LLaVA-NeXT and different curated knowledge for coaching. The reasoning agent goals to offer finalized step-by-step processes for fixing logical issues, whereas the abstract agent critically evaluates and polishes these steps to scale back errors. Coaching begins with role-specific supervised fine-tuning, progressively shifting to iterative desire optimization, refining the output to be nearer to precise human decision-making. This model of coaching maintains a structured strategy towards strong generalization throughout domains and complicated reasoning duties.
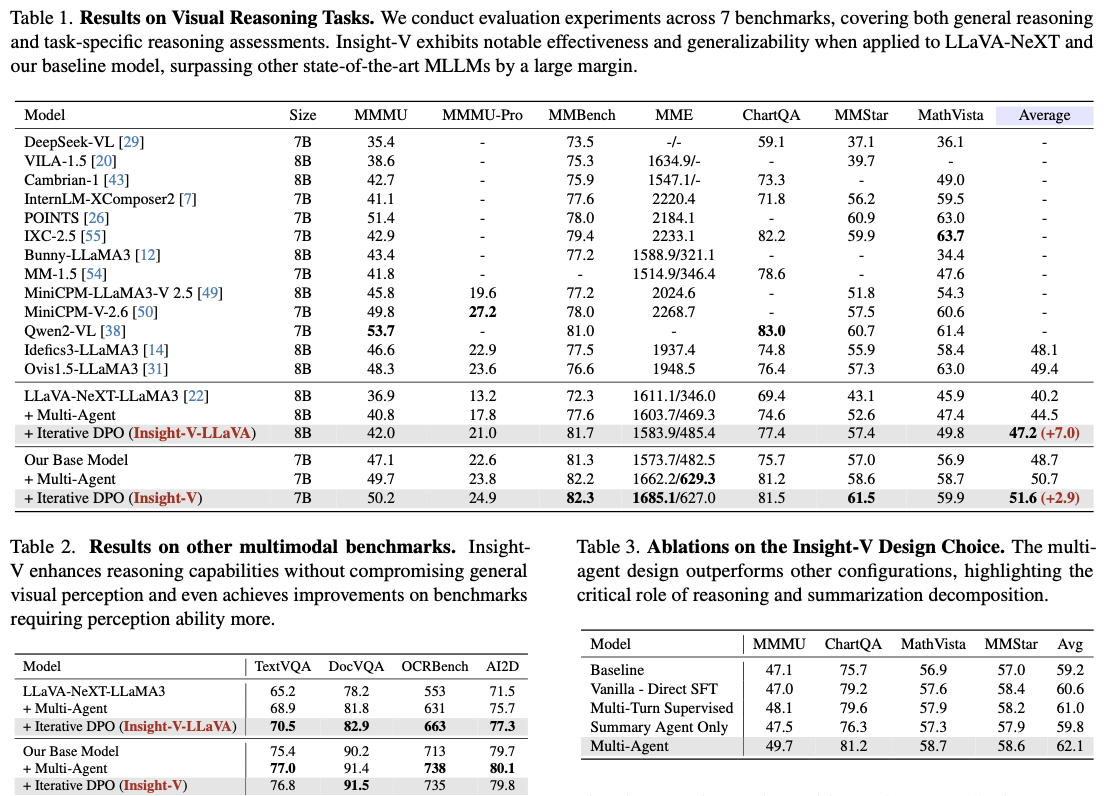
Multi-modal reasoning efficiency enchancment of the system on benchmark duties is main with a imply relative enchancment of seven.0% over LLaVA-NeXT and a pair of.9% from the baseline mannequin. Perception-V improves efficiency over duties corresponding to chart-oriented detailed evaluation and mathematical reasoning moreover generalization functionality in perception-focused analysis modules like TextVQA. That is the explanation for regular efficiency enchancment throughout these duties that validates the utility and benefit of the system, therefore its placement firmly as a trademark growth in multi-modal reasoning fashions.
Perception-V affords a transformative framework for addressing key challenges in multi-modal reasoning by integrating modern knowledge technology strategies with a collaborative multi-agent structure. Improved reasoning over structured datasets, task-specific decomposition, and reinforcement studying optimizations are important contributions within the context. This work ensures that MLLMs will certainly face reasoning-intensive duties successfully whereas being versatile throughout completely different domains. In that regard, Perception-V serves as the essential foundation for additional growth towards constructing techniques that make the most of complicated reasoning inside difficult visual-linguistic environments.
Try the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Neglect to affix our 55k+ ML SubReddit.
[FREE AI VIRTUAL CONFERENCE] SmallCon: Free Digital GenAI Convention ft. Meta, Mistral, Salesforce, Harvey AI & extra. Be a part of us on Dec eleventh for this free digital occasion to study what it takes to construct massive with small fashions from AI trailblazers like Meta, Mistral AI, Salesforce, Harvey AI, Upstage, Nubank, Nvidia, Hugging Face, and extra.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Expertise, Kharagpur. He’s captivated with knowledge science and machine studying, bringing a powerful educational background and hands-on expertise in fixing real-life cross-domain challenges.









{kind=link}