
Spoken time period detection (STD) is a crucial space in speech processing, enabling the identification of particular phrases or phrases in giant audio archives. This expertise is extensively utilized in voice-based searches, transcription companies, and multimedia indexing purposes. By facilitating the retrieval of spoken content material, STD performs a pivotal position in bettering the accessibility and value of audio information, particularly in domains like podcasts, lectures, and broadcast media.
A major problem in spoken time period detection is the efficient dealing with of out-of-vocabulary (OOV) phrases and the computational calls for of present methods. Conventional strategies typically depend upon automated speech recognition (ASR) methods, that are resource-intensive and susceptible to errors, notably for short-duration audio segments or underneath variable acoustic situations. Additional, these strategies need assistance precisely section steady speech, making figuring out particular phrases with out context troublesome.
Present approaches to STD embrace ASR-based methods that use phoneme or grapheme lattices, in addition to dynamic time warping (DTW) and acoustic phrase embeddings for direct audio comparisons. Whereas these strategies have their deserves, they’re restricted by speaker variability, computational inefficiency, and challenges in processing giant datasets. Present instruments additionally need assistance generalizing to completely different datasets, particularly for phrases not encountered throughout coaching.
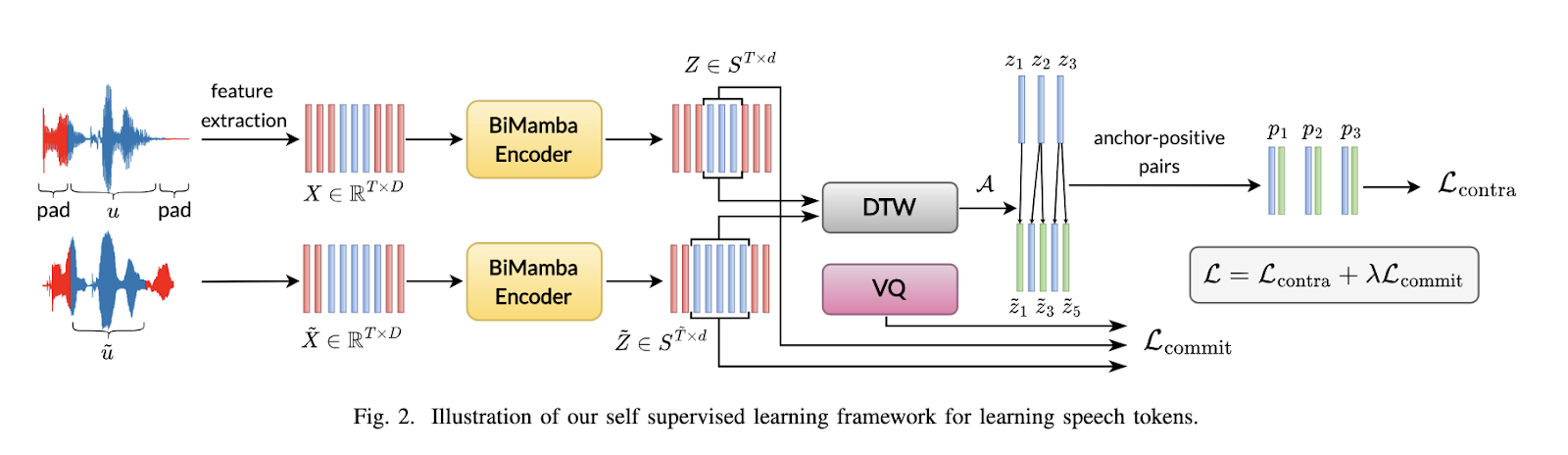
Researchers from the Indian Institute of Know-how Kanpur and imec – Ghent College have launched a novel speech tokenization framework named BEST-STD. This strategy encodes speech into discrete, speaker-agnostic semantic tokens, enabling environment friendly retrieval with text-based algorithms. By incorporating a bidirectional Mamba encoder, the framework generates extremely constant token sequences throughout completely different utterances of the identical time period. This methodology eliminates the necessity for express segmentation and handles OOV phrases extra successfully than earlier methods.
The BEST-STD system makes use of a bidirectional Mamba encoder, which processes audio enter in each ahead and backward instructions to seize long-range dependencies. Every layer of the encoder initiatives audio information into high-dimensional embeddings, that are discretized into token sequences by way of a vector quantizer. The mannequin employs a self-supervised studying strategy, leveraging dynamic time warping to align utterances of the identical time period and create frame-level anchor-positive pairs. The system makes use of an inverted index for storing tokenized sequences, permitting for environment friendly retrieval by evaluating token similarity. Throughout coaching, the system generates constant token representations, guaranteeing invariance to the speaker and acoustic variations.
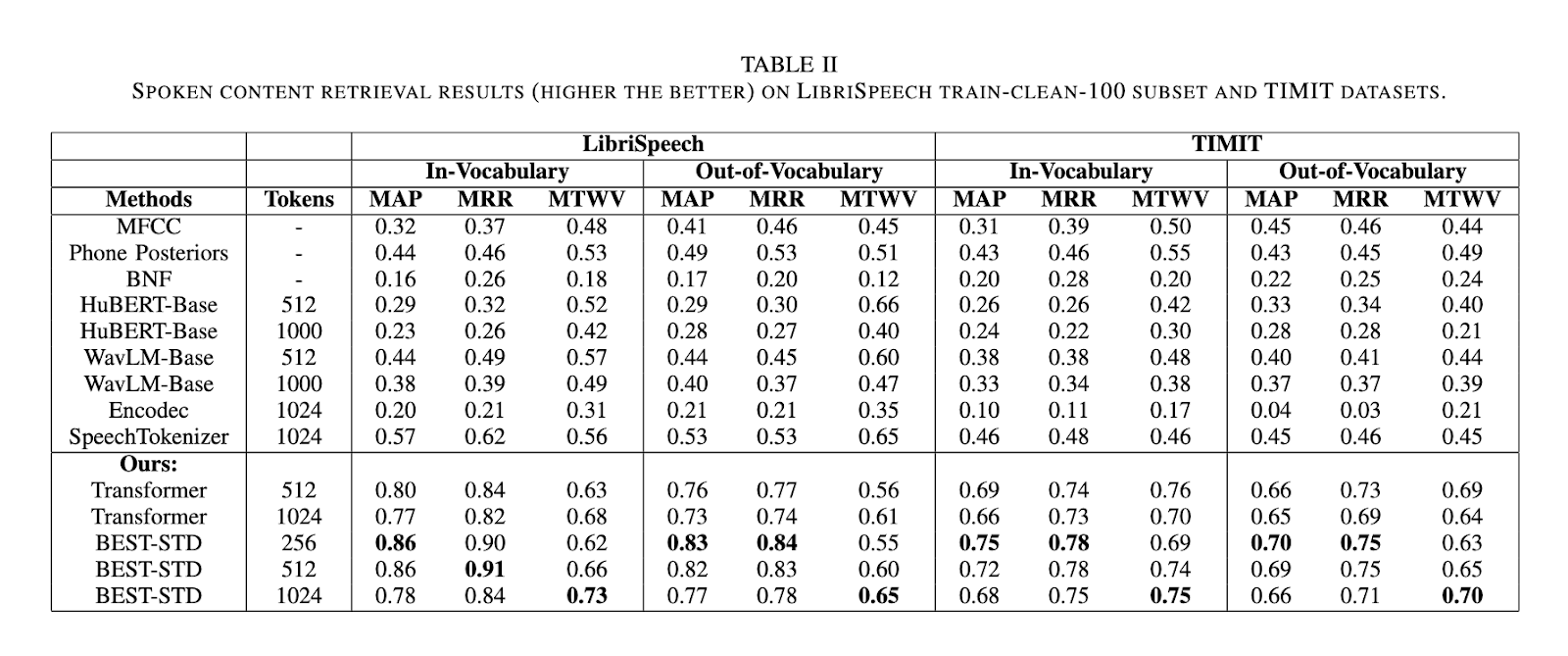
The BEST-STD framework demonstrated superior efficiency in evaluations performed on the LibriSpeech and TIMIT datasets. In comparison with conventional STD strategies and state-of-the-art tokenization fashions like HuBERT, WavLM, and SpeechTokenizer, BEST-STD achieved considerably greater Jaccard similarity scores for token consistency, with unigram scores reaching 0.84 and bigram scores at 0.78. The system outperformed baselines on spoken content material retrieval duties in imply common precision (MAP) and imply reciprocal rank (MRR). For in-vocabulary phrases, BEST-STD achieved MAP scores of 0.86 and MRR scores of 0.91 on the LibriSpeech dataset, whereas for OOV phrases, the scores reached 0.84 and 0.90 respectively. These outcomes underline the system’s skill to successfully generalize throughout completely different time period varieties and datasets.
Notably, the BEST-STD framework additionally excelled in retrieval pace and effectivity, benefiting from an inverted index for tokenized sequences. This strategy decreased reliance on computationally intensive DTW-based matching, making it scalable for big datasets. The bidirectional Mamba encoder, specifically, proved simpler than transformer-based architectures on account of its skill to mannequin fine-grained temporal data crucial for spoken time period detection.
In conclusion, the introduction of BEST-STD marks a major development in spoken time period detection. By addressing the restrictions of conventional strategies, this strategy affords a strong & environment friendly answer for audio retrieval duties. The usage of speaker-agnostic tokens and a bidirectional Mamba encoder not solely enhances efficiency but in addition ensures adaptability to numerous datasets. This framework demonstrates promise for real-world purposes, paving the way in which for improved accessibility and searchability in audio processing.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. When you like our work, you’ll love our publication.. Don’t Overlook to affix our 55k+ ML SubReddit.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.









{kind=link}