
Reasoning is essential in problem-solving, permitting people to make selections and derive options. Two main kinds of reasoning are utilized in problem-solving: ahead reasoning and backward reasoning. Ahead reasoning includes working from a given query in direction of an answer, utilizing incremental steps. In distinction, backward reasoning begins with a possible resolution and traces again to the unique query. This method is useful in duties that require validation or error-checking, because it helps determine inconsistencies or missed steps within the course of.
One of many central challenges in synthetic intelligence is incorporating reasoning strategies, particularly backward reasoning, into machine studying fashions. Present methods depend on ahead reasoning, producing solutions from a given information set. Nevertheless, this method can lead to errors or incomplete options, because the mannequin must assess and proper its reasoning path. Introducing backward reasoning into AI fashions, significantly in Giant Language Fashions (LLMs), presents a possibility to enhance the accuracy & reliability of those methods.
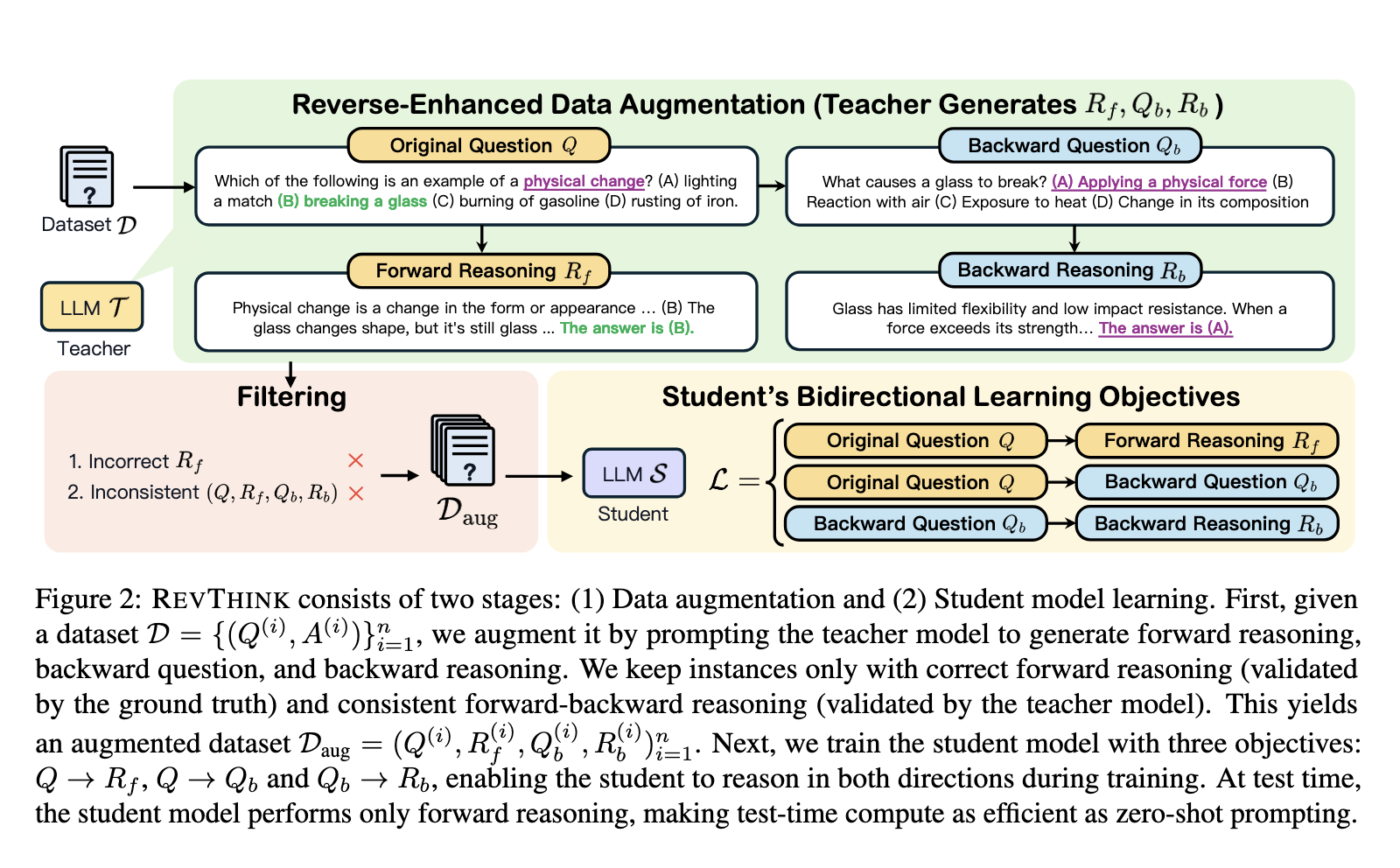
Present strategies for reasoning in LLMs focus totally on ahead reasoning, the place fashions generate solutions based mostly on a immediate. Some methods, equivalent to information distillation, try to enhance reasoning by fine-tuning fashions with appropriate reasoning steps. These strategies are usually employed throughout testing, the place the mannequin’s generated solutions are cross-checked utilizing backward reasoning. Though this improves the mannequin’s accuracy, backward reasoning has but to be integrated into the model-building course of, limiting this method’s potential advantages.
Researchers from UNC Chapel Hill, Google Cloud AI Analysis, and Google DeepMind launched the Reverse-Enhanced Considering (REVTINK) framework. Developed by the Google Cloud AI Analysis and Google DeepMind groups, REVTINK integrates backward reasoning straight into the coaching of LLMs. As a substitute of utilizing backward reasoning merely as a validation software, this framework incorporates it into the coaching course of by educating fashions to deal with each ahead and backward reasoning duties. The purpose is to create a extra sturdy and environment friendly reasoning course of that can be utilized to generate solutions for all kinds of duties.
The REVTINK framework trains fashions on three distinct duties: producing ahead reasoning from a query, a backward query from an answer, and backward reasoning. By studying to purpose in each instructions, the mannequin turns into more proficient at tackling complicated duties, particularly these requiring a step-by-step verification course of. The twin method of ahead and backward reasoning enhances the mannequin’s capacity to test and refine its outputs, finally main to raised accuracy and diminished errors.
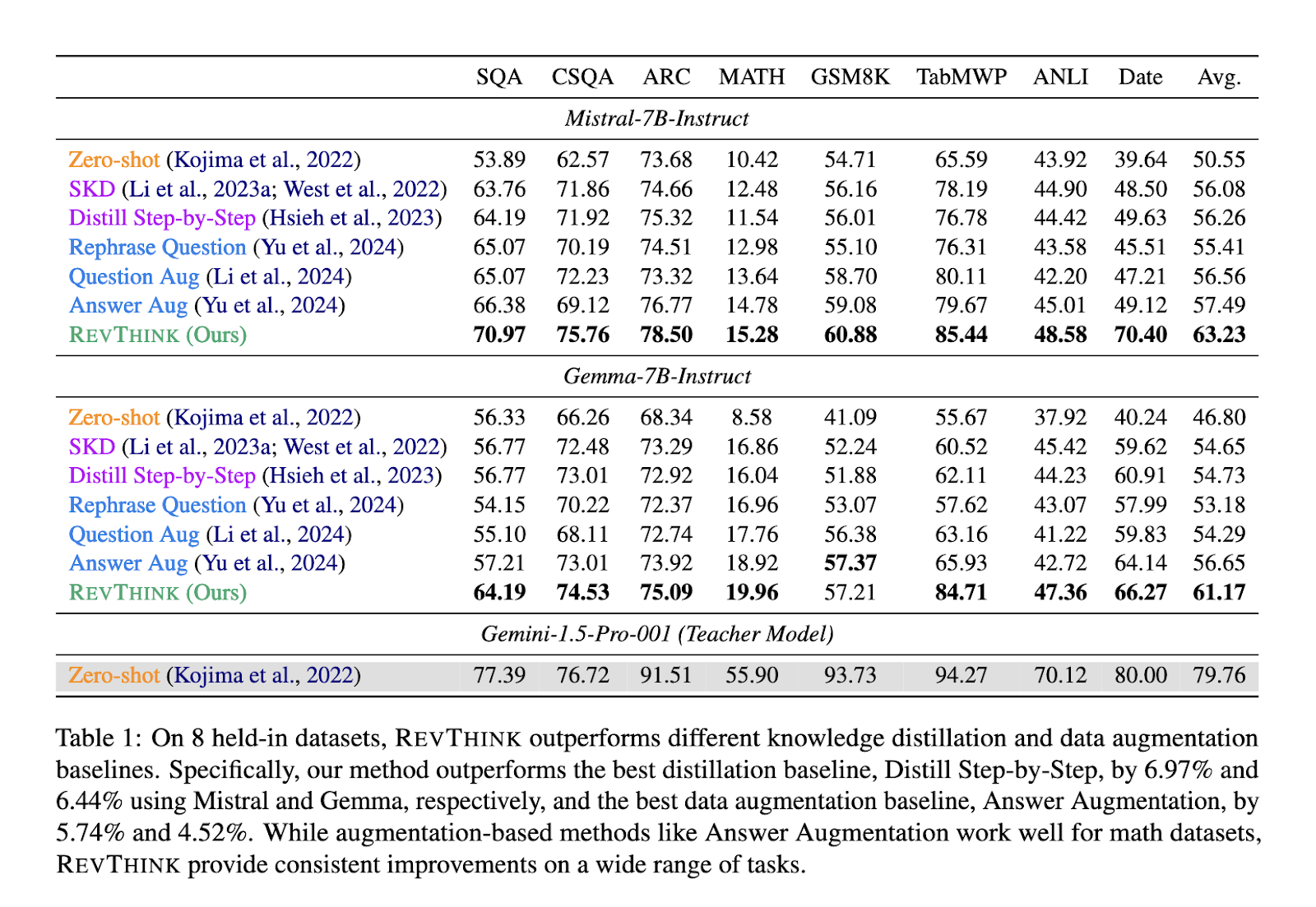
Efficiency checks on REVTINK confirmed important enhancements over conventional strategies. The analysis crew evaluated the framework on 12 various datasets, which included duties associated to commonsense reasoning, mathematical problem-solving, and logical duties. In comparison with zero-shot efficiency, the mannequin achieved a median enchancment of 13.53%, showcasing its capacity to grasp higher and generate solutions for complicated queries. The REVTINK framework outperformed robust information distillation strategies by 6.84%, highlighting its superior efficiency. Moreover, the mannequin was discovered to be extremely environment friendly by way of pattern utilization. It required considerably much less coaching information to attain these outcomes, making it a extra environment friendly possibility than conventional strategies that depend on bigger datasets.
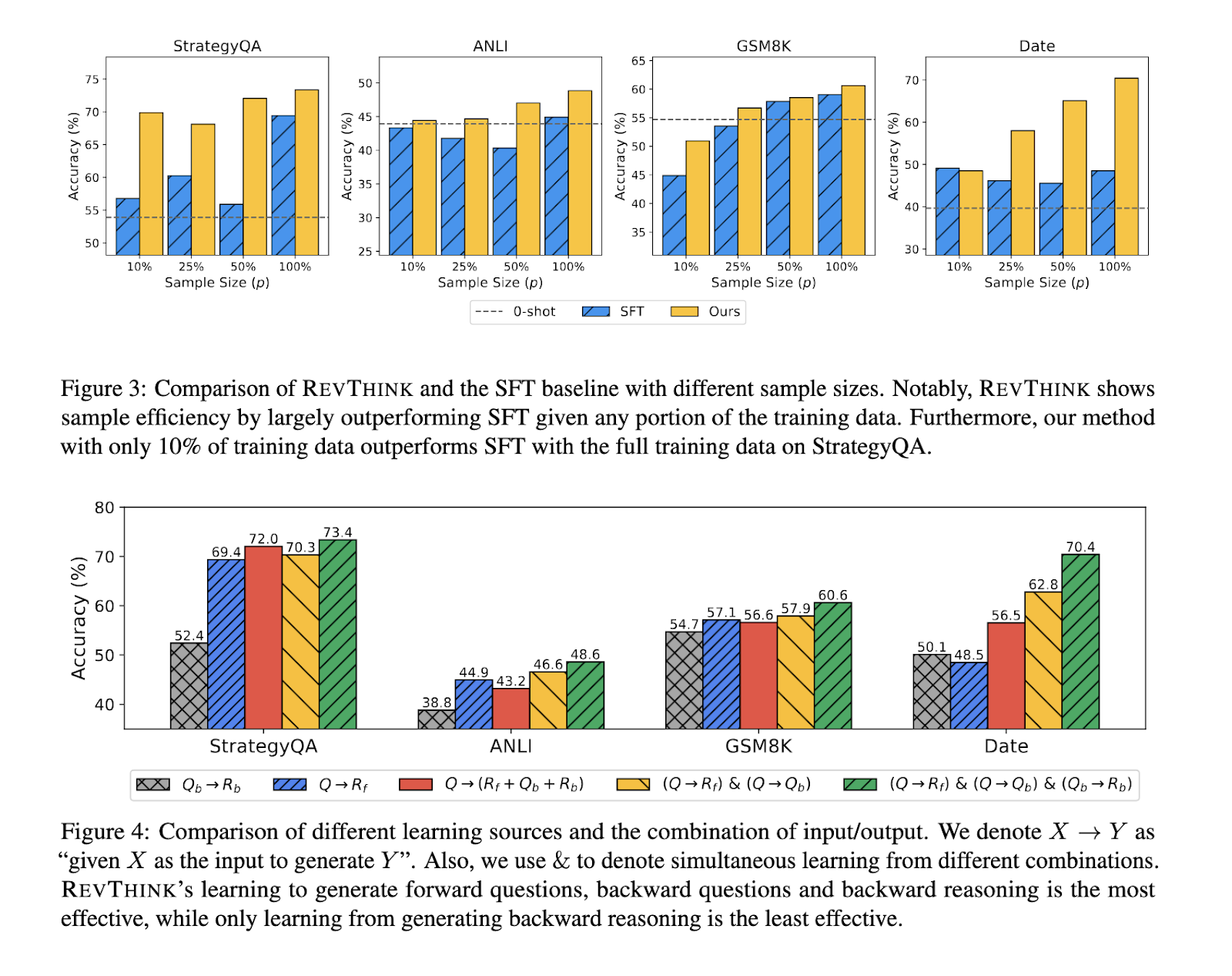
Concerning particular metrics, the REVTINK mannequin’s efficiency throughout totally different domains additionally illustrated its versatility. The mannequin confirmed a 9.2% enchancment in logical reasoning duties over standard fashions. It demonstrated a 14.1% improve in accuracy for commonsense reasoning, indicating its robust capacity to purpose via on a regular basis conditions. The strategy’s effectivity additionally stood out, requiring 20% much less coaching information whereas outperforming earlier benchmarks. This effectivity makes REVTINK a pretty possibility for purposes the place coaching information is likely to be restricted or costly.
The introduction of REVTINK marks a big development in how AI fashions deal with reasoning duties. The mannequin can generate extra correct solutions utilizing fewer sources by integrating backward reasoning into the coaching course of. The framework’s capacity to enhance efficiency throughout a number of domains—particularly with much less information—demonstrates its potential to revolutionize AI reasoning. Total, REVTINK guarantees to create extra dependable AI methods that deal with varied duties, from mathematical issues to real-world decision-making.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to comply with us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 60k+ ML SubReddit.
🚨 [Must Attend Webinar]: ‘Remodel proofs-of-concept into production-ready AI purposes and brokers’ (Promoted)
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.









{kind=link}