
Massive language fashions (LLMs) have turn into essential instruments for purposes in pure language processing, computational arithmetic, and programming. Such fashions usually require large-scale computational assets to execute inference and prepare the mannequin effectively. To scale back this, many researchers have devised methods to optimize the methods used with these fashions.
A robust problem in LLM optimization arises from the truth that conventional pruning strategies are mounted. Static Pruning removes pointless parameters based mostly on a prespecified masks. They can’t be utilized if the required talent for an software is coding or fixing mathematical issues. These strategies lack flexibility, because the efficiency is often not maintained for a number of duties whereas optimizing the computational assets.
Traditionally, methods similar to static structured Pruning and mixture-of-experts (MoE) architectures have been used to counter the computational inefficiencies of LLMs. Structured Pruning removes parts like channels or consideration heads from particular layers. Though these strategies are hardware-friendly, they require full retraining to keep away from a lack of mannequin accuracy. MoE fashions, in flip, activate elements of the mannequin throughout inference however incur enormous overheads from frequent parameter reloading.
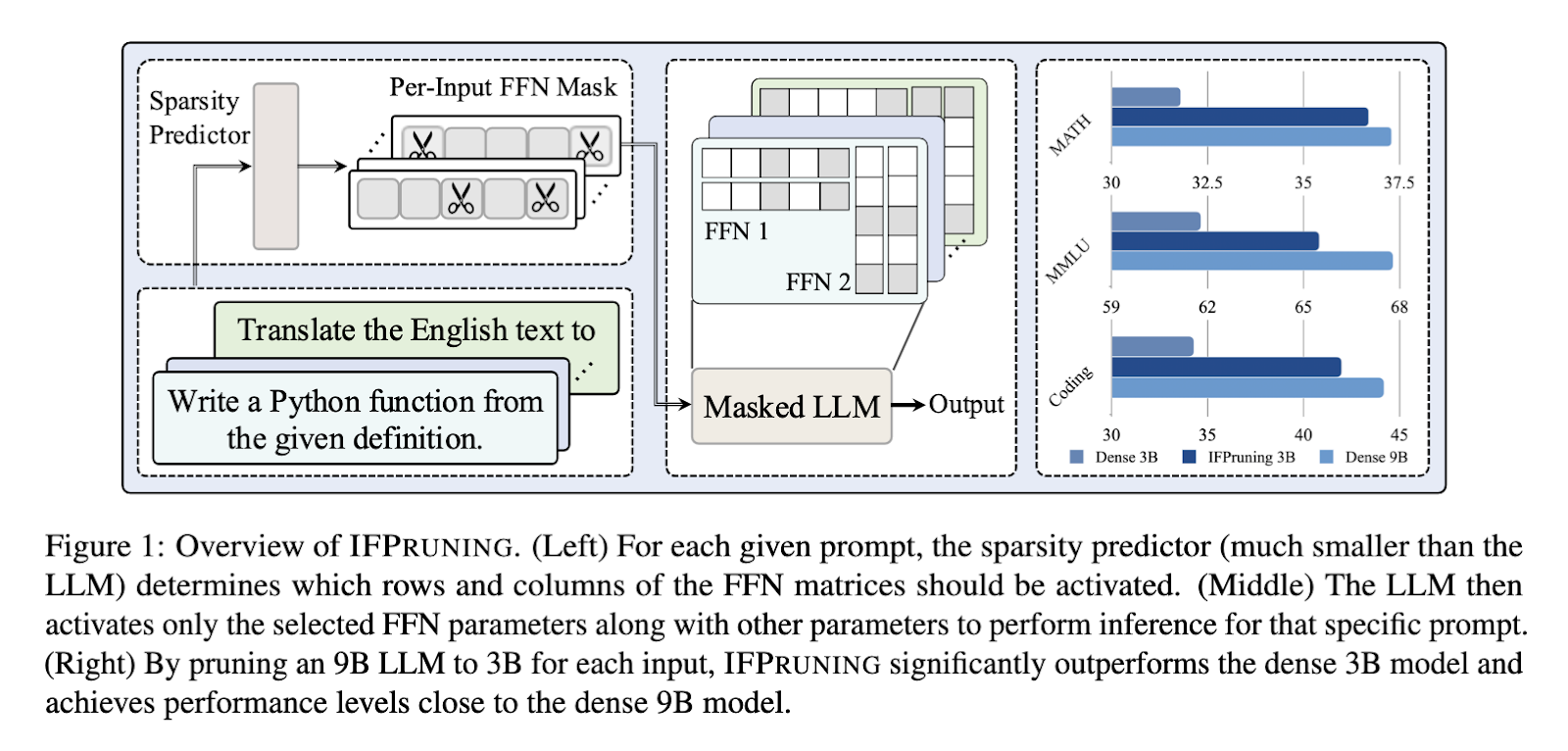
Apple AI and UC Santa Barbara researchers have launched a brand new approach known as Instruction-Following Pruning (IFPruning), which dynamically adapts LLMs to the wants of a selected activity. IFPruning makes use of a sparsity predictor that generates input-dependent pruning masks, choosing solely probably the most related parameters for a given activity. Not like conventional strategies, this dynamic method focuses on feed-forward neural community (FFN) layers, permitting the mannequin to adapt to various duties whereas lowering computational calls for effectively.
The researchers suggest a two-stage coaching course of for IFPruning: First, proceed pre-training dense fashions on giant knowledge, maximizing the sparsity predictor and the LLM. This produces a robust start line for subsequent fine-tuning. In stage two, coaching is carried out solely on supervised fine-tuning datasets, utilizing extremely different activity prompts and a number of examples. Masking remains to be dynamic because of the on-line technology of sparsity predictors pruning out pointless weights with out affecting mannequin efficiency. This eliminates the necessity for parameter reloading, a limitation noticed in prior dynamic strategies.
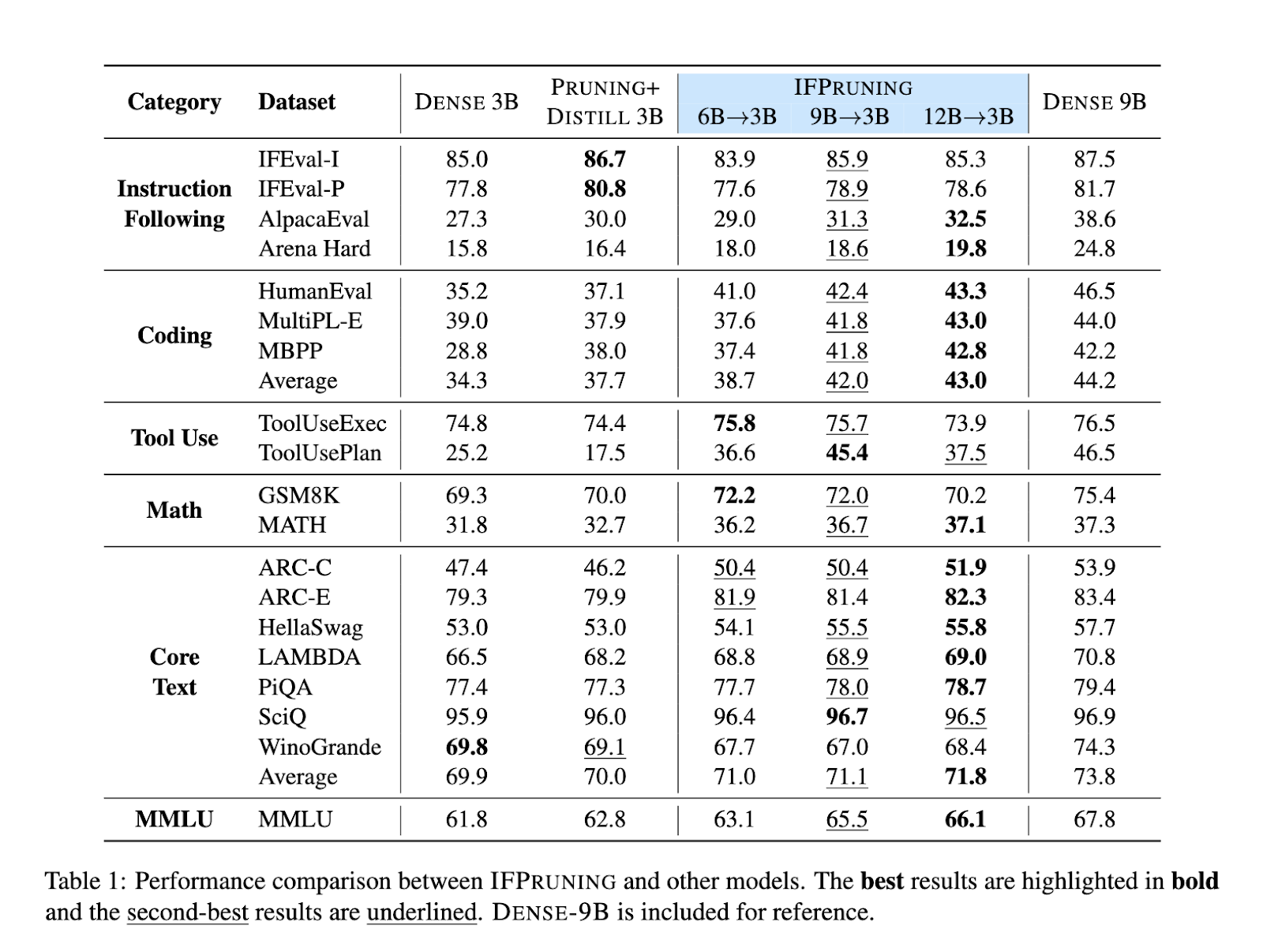
The efficiency of IFPruning was rigorously evaluated throughout a number of benchmarks. As an illustration, pruning a 9B parameter mannequin to 3B improved coding activity accuracy by 8% in comparison with a dense 3B mannequin, intently rivaling the unpruned 9B mannequin. On mathematical datasets like GSM8K and MATH, the dynamic pruning method yielded a 5% improve in accuracy. It exhibited constant good points on instruction-following analysis in each IFEval and AlpacaEval for round 4-6 p.c factors. Even with multi-task benchmarks like MMLU, it confirmed promising sturdy outcomes of IFPruning, displaying versatility throughout different domains.
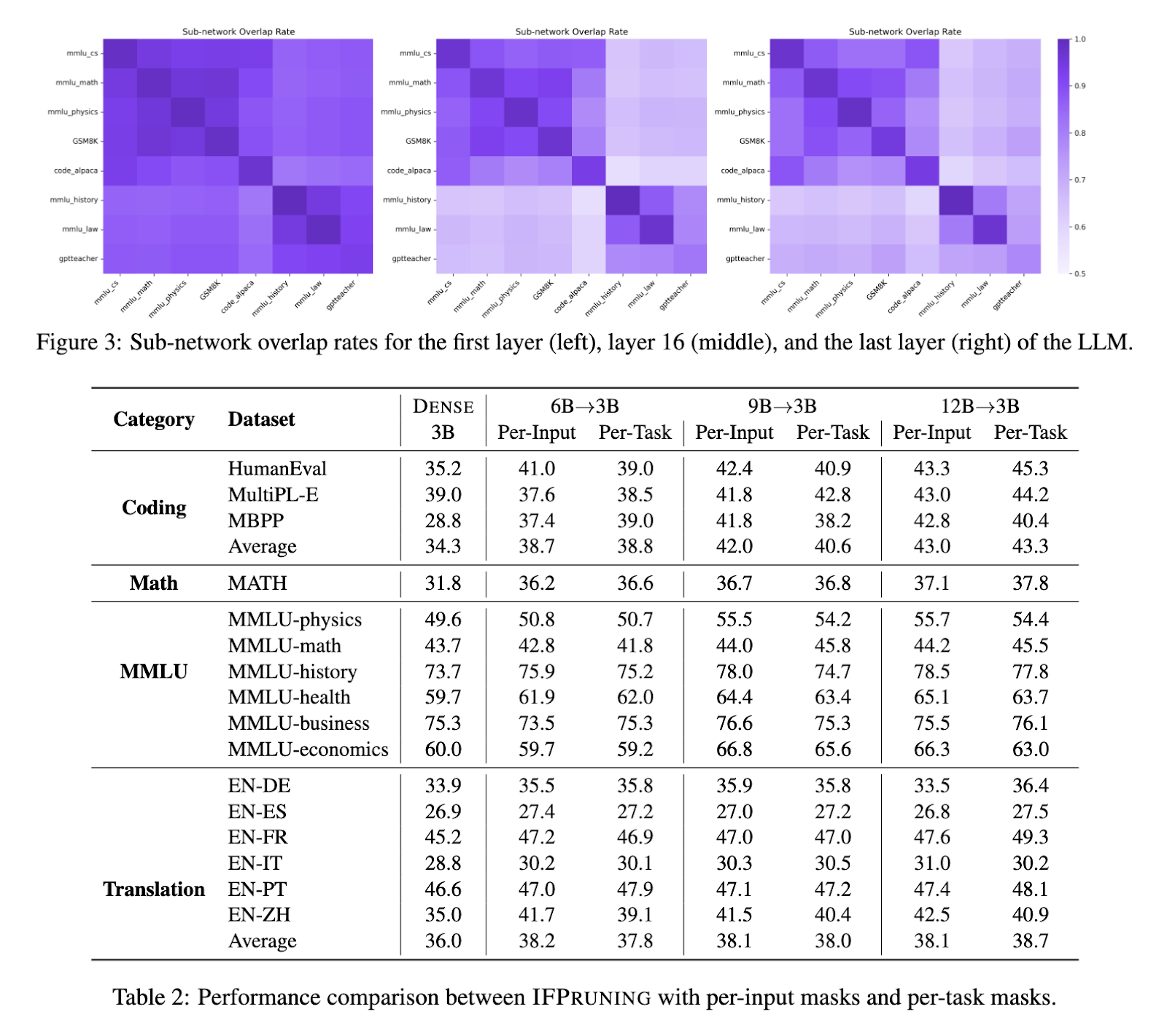
These outcomes underpin the IFPruning method’s scalability since fashions with various sizes, specifically 6B, 9B, and 12B parameters, have been examined; in all, essential efficiency enhancements post-pruning are achieved. Scaling from a 6B dense mannequin to a 12B dense mannequin confirmed that, beneath the identical situation, effectivity was improved together with task-specific accuracy. It additional outperformed conventional structured pruning strategies like Pruning + Distill as a consequence of using a dynamic sparsity mechanism.
The introduction of IFPruning marks a major development in optimizing LLMs, offering a way that dynamically balances effectivity and efficiency. The method addresses the constraints of static pruning and MoE architectures, setting a brand new normal for resource-efficient language fashions. With its capacity to adapt to different inputs with out sacrificing accuracy, IFPruning presents a promising resolution for deploying LLMs on resource-constrained units.
This analysis will level out additional developments in mannequin pruning, which embody optimizing different parts, similar to consideration heads and hidden layers. Despite the fact that the methodology introduced immediately tackles most of the computational challenges, additional analysis in server-side purposes and multi-task Pruning can broaden its scope of applicability. As a dynamic and environment friendly framework, IFPruning opens up prospects for extra adaptive and accessible large-scale language fashions.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 65k+ ML SubReddit.
🚨 FREE UPCOMING AI WEBINAR (JAN 15, 2025): Increase LLM Accuracy with Artificial Knowledge and Analysis Intelligence–Be a part of this webinar to achieve actionable insights into boosting LLM mannequin efficiency and accuracy whereas safeguarding knowledge privateness.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Know-how, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching purposes in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.









{kind=link}