
Amazon SageMaker gives a seamless expertise for constructing, coaching, and deploying machine studying (ML) fashions at scale. Though SageMaker gives a variety of built-in algorithms and pre-trained fashions by Amazon SageMaker JumpStart, there are eventualities the place you would possibly must convey your individual customized mannequin or use particular software program dependencies not obtainable in SageMaker managed container photos. Examples for this might embody use circumstances like geospatial evaluation, bioinformatics analysis, or quantum machine studying. In such circumstances, SageMaker means that you can prolong its performance by creating customized container photos and defining customized mannequin definitions. This method allows you to bundle your mannequin artifacts, dependencies, and inference code right into a container picture, which you’ll deploy as a SageMaker endpoint for real-time inference. This submit walks you thru the end-to-end technique of deploying a single customized mannequin on SageMaker utilizing NASA’s Prithvi mannequin. The Prithvi mannequin is a first-of-its-kind temporal Imaginative and prescient transformer pre-trained by the IBM and NASA group on contiguous US Harmonised Landsat Sentinel 2 (HLS) knowledge. It may be finetuned for picture segmentation utilizing the mmsegmentation library to be used circumstances like burn scars detection, flood mapping, and multi-temporal crop classification. Resulting from its distinctive structure and fine-tuning dependency on the MMCV library, it’s an efficient instance of learn how to deploy advanced customized fashions to SageMaker. We exhibit learn how to use the pliability of SageMaker to deploy your individual customized mannequin, tailor-made to your particular use case and necessities. Whether or not you’re working with distinctive mannequin architectures, specialised libraries, or particular software program variations, this method empowers you to harness the scalability and administration capabilities of SageMaker whereas sustaining management over your mannequin’s surroundings and dependencies.
Answer overview
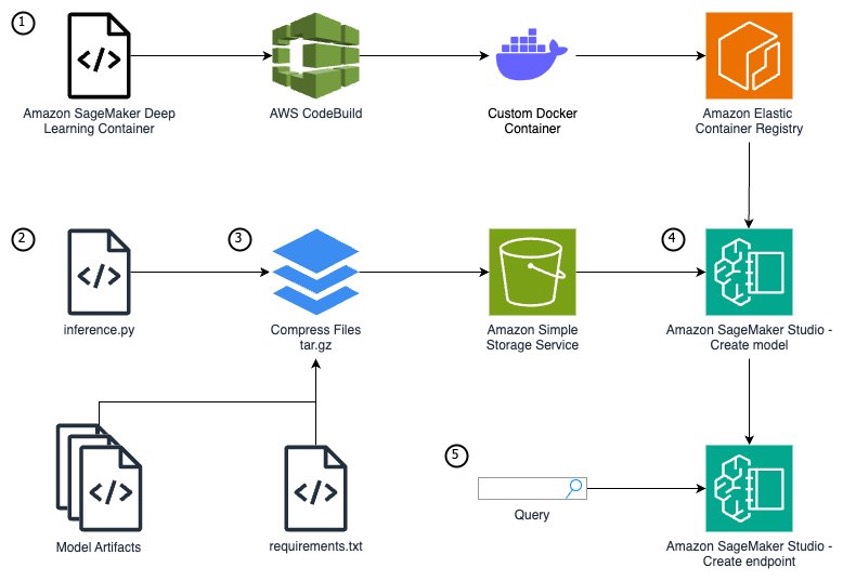
To run a customized mannequin that wants distinctive packages as a SageMaker endpoint, you must comply with these steps:
- In case your mannequin requires further packages or bundle variations unavailable from the SageMaker managed container photos, you have to to increase one of many container photos. By extending a SageMaker managed container vs. creating one from scratch, you’ll be able to focus in your particular use case and mannequin improvement as an alternative of the container infrastructure.
- Write a Python mannequin definition utilizing the SageMaker
inference.pyfile format. - Outline your mannequin artifacts and inference file inside a particular file construction, archive your mannequin recordsdata as a tar.gz file, and add your recordsdata to Amazon Easy Storage Service (Amazon S3).
- Together with your mannequin code and an prolonged SageMaker container, use Amazon SageMaker Studio to create a mannequin, endpoint configuration, and endpoint.
- Question the inference endpoint to verify your mannequin is working accurately.
The next diagram illustrates the answer structure and workflow:
Stipulations
You want the next conditions earlier than you’ll be able to proceed. For this submit, we use the us-east-1 AWS Area:
- Have entry to a POSIX primarily based (Mac/Linux) system or SageMaker notebooks. This submit doesn’t cowl organising SageMaker entry and assumes a pocket book accessible to the web. Nevertheless, this isn’t a safety greatest apply and shouldn’t be carried out in manufacturing. To learn to create a SageMaker pocket book inside a digital non-public cloud (VPC), see Hook up with SageMaker AI Inside your VPC.
- Ensure you have AWS Id and Entry Administration (IAM) permissions for SageMaker entry; S3 bucket create, learn, and PutObject entry; AWS CodeBuild entry; Amazon Elastic Container Registry (Amazon ECR) repository entry; and the flexibility to create IAM roles.
- Obtain the Prithvi mannequin artifacts and flood knowledge fine-tuning:
Prolong a SageMaker container picture in your mannequin
Though AWS gives pre-built container photos optimized for deep studying on the AWS Deep Studying Containers (DLCs) GitHub for PyTorch and TensorFlow use circumstances, there are eventualities the place fashions require further libraries not included in these containers. The set up of those dependencies can take minutes or hours, so it’s extra environment friendly to pre-build these dependencies right into a customized container picture. For this instance, we deploy the Prithvi mannequin, which depends on the MMCV library for superior laptop imaginative and prescient methods. This library shouldn’t be obtainable inside any of the SageMaker DLCs, so you’ll have to create an prolonged container so as to add it. Each MMCV and Prithvi are third-party fashions which haven’t undergone AWS safety evaluations, so please evaluation these fashions your self or use at your individual danger. This submit makes use of CodeBuild and a Docker Dockerfile to construct the prolonged container.
Full the next steps:
- CodeBuild requires a supply location containing the supply code. Create an S3 bucket to function this supply location utilizing the next instructions:
- Create an ECR repository to retailer the customized container picture produced by the CodeBuild challenge. Document the repository URI as an surroundings variable.
- Create a Dockerfile for the customized container. You utilize an AWS Deep Studying SageMaker framework container as the bottom picture as a result of it consists of required dependencies similar to SageMaker libraries, PyTorch, and CUDA.
This Docker container installs the Prithvi mannequin and MMCV v1.6.2. These fashions are third-party fashions not produced by AWS and subsequently might have safety vulnerabilities. Use at your individual danger.
- Create a
buildspecfile to outline the construct course of for the CodeBuild challenge. Thisbuildspecfile will instruct CodeBuild to put in thenvidia-container-toolkitto verify the Docker container has GPU entry, run the Dockerfile construct, and push the constructed container picture to your ECR repository. - Zip and add the Dockerfile and
buildspec.ymlrecordsdata to the S3 bucket. This zip file will function the supply code for the CodeBuild challenge.- To put in zip on a SageMaker pocket book, run the next command:
- With zip put in, run the next command:
- Create a CodeBuild service position so CodeBuild can entry the required AWS companies for the construct.
- First, create a file defining the position’s belief coverage:
- Create a file defining the service position’s permissions. This position has a couple of wildcard permissions (/* or *). These may give extra permissions than wanted and break the rule of least privilege. For extra details about defining least privilege for manufacturing use circumstances, see Grant least privilege.
- Create the CodeBuild service position:
- Seize the title of the position Amazon Useful resource Identify (ARN) from the CLI command response and document as an surroundings variable:
- Connect the permission insurance policies to the service position:
- Outline the configurations for the CodeBuild construct challenge utilizing the construct challenge JSON specification:
- Create the CodeBuild challenge utilizing the
codebuild-project.jsonspecification outlined within the earlier step: - Run a construct for the CodeBuild challenge:
The construct will take roughly half-hour to finish and value roughly $1.50 to run. The CodeBuild compute occasion sort gpu1.small prices $0.05 per minute.
After you run the previous command, you’ll be able to press Ctrl+C to exit and run future instructions. The construct will already be working on AWS and won’t be canceled by closing the command.
- Monitor the standing of the construct utilizing the next command and wait till you observe
buildStatus=SUCCEEDEDearlier than continuing to the following step:
After your CodeBuild challenge has accomplished, just remember to don’t shut your terminal. The surroundings variables right here will probably be used once more.
Construct your inference.py file
To run a customized mannequin for inference on AWS, you must construct out an inference.py file that initializes your mannequin, defines the enter and output construction, and produces your inference outcomes. On this file, you need to outline 4 capabilities:
model_fn– Initializes your mannequin-
input_fn– Defines how your knowledge needs to be enter and learn how to convert to a usable format predict_fn– Takes the enter knowledge and receives the predictionoutput_fn– Converts the prediction into an API name format
We use the next accomplished inference.py file for the SageMaker endpoint on this submit. Obtain this inference.py to proceed as a result of it consists of the helper capabilities to course of the TIFF recordsdata wanted for this mannequin’s enter. The next code is contained throughout the inference.py and is barely proven to supply an evidence of what’s being carried out within the file.
model_fn
The model_fn perform builds your mannequin, which known as and used throughout the predict_fn perform. This perform hundreds the mannequin weights right into a torch mannequin checkpoint, opens the mannequin config, defines international variables, instantiates the mannequin, hundreds the mannequin checkpoint into the mannequin, and returns the mannequin.
input_fn
This perform defines the anticipated enter for the mannequin and learn how to load the enter to be used in predict_fn. The endpoint expects a string URL path linked to a TIFF file you will discover on-line from the Prithvi demo on Hugging Face. This perform additionally defines the content material sort of the request despatched within the physique (similar to software/json, picture/tiff).
predict_fn:
In predict_fn, you create the prediction from the given enter. On this case, creating the prediction picture makes use of two helper capabilities particular to this endpoint (preprocess_image and enhance_raster_for_visualization). You’ll find each capabilities right here. The preprocess_image perform normalizes the picture, then the perform makes use of torch.no_grad to disable gradient calculations for the mannequin. That is helpful throughout inference to lower inference time and cut back reminiscence utilization. Subsequent, the perform collects the prediction from the instantiated mannequin. The masks ratio determines the variety of pixels on the picture zeroed out throughout inference. The 2 unpatchify capabilities convert the smaller patchified outcomes produced by the mannequin again to the unique picture house. The perform normalized.clone() clones the normalized photos and replaces the masked Areas from rec_img with the Areas from the pred_img. Lastly, the perform reshapes the picture again into TIFF format, removes the normalization, and returns the picture in raster format, which is effective for visualization. The results of that is a picture that may be transformed to bytes for the person after which visualized on the person’s display.
output_fn
output_fn returns the TIFF picture obtained from predict_fn as an array of bytes.
Take a look at your inference.py file
Now that you’ve downloaded the whole inference.py file, there are two choices to check your mannequin earlier than compressing the recordsdata and importing them to Amazon S3:
- Take a look at the
inference.pycapabilities in your customized container inside an Amazon Elastic Compute Cloud (Amazon EC2) occasion - Take a look at your endpoint on an area mode SageMaker endpoint (requires a GPU or GPU-based workspace for this mannequin)
Mannequin file construction, tar.gz compressing, and S3 add
Earlier than you begin this step, obtain the Prithvi mannequin artifacts and the Prithvi flood fine-tuning of the mannequin. The primary hyperlink will present all the mannequin knowledge from the bottom Prithvi mannequin, and the flood fine-tuning of the mannequin builds upon the mannequin to carry out flood plain detection on satellite tv for pc photos. Set up git-lfs utilizing brew on Mac or utilizing https://git-lfs.com/ on Home windows to put in the GitHub repo’s giant recordsdata.
To create a SageMaker mannequin on the SageMaker console, you need to retailer your mannequin knowledge inside Amazon S3 as a result of your SageMaker endpoint will pull your mannequin artifacts instantly from Amazon S3 utilizing a tar.gz format. Inside your tar.gz file, the information should have a particular file format outlined by SageMaker. The next is the file construction for the Prithvi basis mannequin (our necessities are put in on the container, so necessities.txt has been left deliberately clean):
This folder construction stays true for different fashions as nicely. The /code folder should maintain the inference.py file and any recordsdata used inside inference.py. These further recordsdata are usually mannequin artifacts (configs, weights, and so forth). In our case, this would be the complete Prithvi base mannequin folder in addition to the weights and configs for the fine-tuned model we are going to use. As a result of now we have already put in these packages inside our container, this isn’t used; nonetheless, there nonetheless should be a necessities.txt file, in any other case your endpoint will fail to construct. All different recordsdata belong within the root folder.
With the previous file construction in place, open your terminal and route into the mannequin folder.
- Run the next command in your terminal:
The command will create a compressed model of your mannequin recordsdata referred to as
mannequin.tar.gzfrom the recordsdata in your present listing. Now you can add this file into an S3 bucket. - If utilizing SageMaker, run the next command:
- Now create a brand new S3 bucket. The next CLI instructions create an S3 bucket and add your
mannequin.tar.gzfile:
The file you uploaded will probably be used within the subsequent step to outline the mannequin to be created within the endpoint.
Create SageMaker mannequin, SageMaker endpoint configuration, and SageMaker endpoint
You now create a SageMaker inference endpoint utilizing the CLI. There are three steps to making a SageMaker endpoint: create a mannequin, create an endpoint configuration, and create an endpoint.
On this submit, you’ll create a public SageMaker endpoint as a result of this can simplify working and testing the endpoint. For particulars about learn how to restrict entry to SageMaker endpoints, confer with Deploy fashions with SageMaker Studio.
Full the next steps:
- Get the ECR repository’s ARN:
- Create a job for the SageMaker service to imagine. Create a file defining the position’s belief coverage.
- Create a file defining the service position’s permissions:
- Create the SageMaker service position:
- Connect the permission insurance policies to the service position:
The mannequin definition will embody the position you created, the ECR container picture, and the Amazon S3 location of the
mannequin.tar.gzfile that you simply created beforehand. - Create a JSON file that defines the mannequin and run the create-model command:
A SageMaker endpoint configuration specifies the infrastructure that the mannequin will probably be hosted on. The mannequin will probably be hosted on a ml.g4dn.xlarge occasion for GPU-based acceleration.
- Create the endpoint configuration JSON file and create the SageMaker endpoint configuration:
- Create the SageMaker endpoint by referencing the endpoint configuration created within the earlier step:
The ml.g4dn.xlarge inference endpoint will price $0.736 per hour whereas working. It can take a number of minutes for the endpoint to complete deploying.
- Test the standing utilizing the next command, ready for it to return InService:
When the endpoint’s standing is InService, proceed to the following part.
Take a look at your customized SageMaker inference endpoint
To check your SageMaker endpoint, you’ll question your endpoint with a picture and show it. The next command sends a URL that references a TIFF picture to the SageMaker endpoint, the mannequin sends again a byte array, and the command reforms the byte array into a picture. Open up a pocket book domestically or on Sagemaker Studio JupyterLab. The beneath code will must be run exterior of the command line to view the picture
This Python code creates a predictor object in your endpoint and units the predictor’s serializer to NumPy for the conversion on the endpoint. It queries the predictor object utilizing a payload of a URL pointing to a TIFF picture. You utilize a helper perform to show the picture and improve the raster. It is possible for you to to seek out that helper perform right here. After you add the helper perform, show the picture:
You need to observe a picture that has been taken from a satellite tv for pc.
Clear up
To wash up the sources from this submit and keep away from incurring prices, comply with these steps:
- Delete the SageMaker endpoint, endpoint configuration, and mannequin.
- Delete the ECR picture and repository.
- Delete the
mannequin.tar.gzfile within the S3 bucket that was created. - Delete the
customsagemakercontainer-modelandcustomsagemakercontainer-codebuildsourceS3 buckets.
Conclusion
On this submit, we prolonged a SageMaker container to incorporate customized dependencies, wrote a Python script to run a customized ML mannequin, and deployed that mannequin on the SageMaker container inside a SageMaker endpoint for real-time inference. This resolution produces a working GPU-enabled endpoint for inference queries. You should utilize this identical course of to create customized mannequin SageMaker endpoints by extending different SageMaker containers and writing an inference.py file for brand spanking new customized fashions. Moreover, with changes, you might create a multi-model SageMaker endpoint for customized fashions or run a batch processing endpoint for eventualities the place you run giant batches of queries directly. These options allow you to transcend the most well-liked fashions used in the present day and customise fashions to suit your personal distinctive use case.
Concerning the Authors
 Aidan is a options architect supporting US federal authorities well being clients. He assists clients by creating technical architectures and offering greatest practices on Amazon Internet Companies (AWS) cloud with a concentrate on AI/ML companies. In his free time, Aidan enjoys touring, lifting, and cooking
Aidan is a options architect supporting US federal authorities well being clients. He assists clients by creating technical architectures and offering greatest practices on Amazon Internet Companies (AWS) cloud with a concentrate on AI/ML companies. In his free time, Aidan enjoys touring, lifting, and cooking
 Nate is a options architect supporting US federal authorities sciences clients. He assists clients in creating technical architectures on Amazon Internet Companies (AWS), with a concentrate on knowledge analytics and excessive efficiency computing. In his free time, he enjoys snowboarding and {golfing}.
Nate is a options architect supporting US federal authorities sciences clients. He assists clients in creating technical architectures on Amazon Internet Companies (AWS), with a concentrate on knowledge analytics and excessive efficiency computing. In his free time, he enjoys snowboarding and {golfing}.
 Charlotte is a options architect on the aerospace & satellite tv for pc group at Amazon Internet Companies (AWS), the place she helps clients obtain their mission targets by modern cloud options. Charlotte focuses on machine studying with a concentrate on Generative AI. In her free time, she enjoys touring, portray, and working.
Charlotte is a options architect on the aerospace & satellite tv for pc group at Amazon Internet Companies (AWS), the place she helps clients obtain their mission targets by modern cloud options. Charlotte focuses on machine studying with a concentrate on Generative AI. In her free time, she enjoys touring, portray, and working.









{kind=link}