
Code era utilizing Giant Language Fashions (LLMs) has emerged as a vital analysis space, however producing correct code for complicated issues in a single try stays a major problem. Even expert human builders usually require a number of iterations of trial-and-error debugging to unravel troublesome programming issues. Whereas LLMs have demonstrated spectacular code era capabilities, their self-debugging capacity to investigate incorrect code and make needed corrections continues to be restricted. This limitation is obvious in open-source fashions like StarCoder and CodeLlama, which present considerably decrease self-refinement efficiency in comparison with fashions like GPT-3.5-Turbo.
Present approaches to enhance code era and debugging capabilities in LLMs have adopted a number of distinct paths. LLMs have proven vital success throughout varied code-related duties, together with code era, bug fixing, program testing, and fuzzing. These fashions use intensive pre-training on huge datasets to know patterns and generate contextually related code. Nevertheless, most present work has primarily centered on single-round era reasonably than iterative enchancment. Different strategies like ILF, CYCLE, and Self-Edit have explored supervised fine-tuning approaches whereas options like OpenCodeInterpreter and EURUS have tried to create high-quality multi-turn interplay datasets utilizing superior fashions for fine-tuning functions.
Researchers from Purdue College, AWS AI Labs, and the College of Virginia have proposed LEDEX (studying to self-debug and clarify code), a novel coaching framework designed to boost LLMs’ self-debugging capabilities. The framework builds on the commentary {that a} sequential technique of explaining incorrect code adopted by refinement allows LLMs to investigate and enhance defective code in a greater means. LEDEX implements an automatic pipeline to gather high-quality datasets for code rationalization, and refinement. Furthermore, it combines supervised fine-tuning (SFT) and reinforcement studying (RL) approaches, using profitable and failed trajectories with a specialised reward system that evaluates code rationalization and refinement high quality.
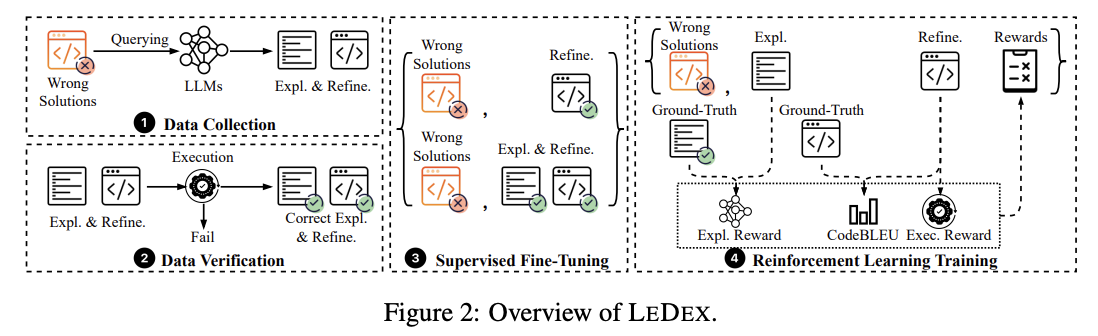
LEDEX employs a complete structure containing information assortment, verification, and multi-stage coaching processes. The framework begins by gathering code rationalization and refinement datasets by means of queries to pre-trained or instruction-tuned fashions. These responses endure rigorous execution-based verification to filter and keep solely high-quality rationalization and refinement information. The collected dataset then serves as enter for supervised fine-tuning which considerably enhances the mannequin’s capabilities in bug rationalization and code refinement. LEDEX makes use of programming issues from MBPP, APPS, and CodeContests to coach information. To develop the dataset of incorrect options, the framework prompts pre-trained LLMs like StarCoder and CodeLlama with 3-shot examples to generate 20 options per drawback.
LEDEX is evaluated utilizing three mannequin backbones: StarCoder-15B, CodeLlama-7B, and CodeLlama-13B, with preliminary coaching information collected from GPT-3.5-Turbo. The SFT section reveals vital enhancements, reaching as much as a 15.92% enhance in move@1 and 9.30% in move@10 metrics throughout 4 benchmark datasets. The next RL section additional enhances efficiency with extra enhancements of as much as 3.54% in move@1 and a couple of.55% in move@10. Notably, LEDEX’s model-agnostic nature is proven by means of experiments with CodeLlama-7B, which obtain substantial enhancements (8.25% in move@1 and a couple of.14% in move@10) even when educated on information collected from CodeLlama-34B or itself, proving its effectiveness impartial of GPT-3.5-Turbo.
In conclusion, researchers launched LEDEX, a complete and scalable framework that mixes automated information assortment, verification processes, SFT, and RL with modern reward designs to considerably enhance LLMs’ capacity to establish and proper code errors. The framework’s model-agnostic nature is evidenced by its profitable implementation with GPT-3.5-Turbo and CodeLlama, whereas its rigorous information verification course of ensures the standard of code explanations and refinements. Human evaluations additional validate the framework’s effectiveness, confirming that LEDEX-trained fashions produce superior code explanations that successfully help builders in understanding and resolving code points.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.

Sajjad Ansari is a ultimate yr undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.









{kind=link}