
Evaluating conversational AI programs powered by giant language fashions (LLMs) presents a important problem in synthetic intelligence. These programs should deal with multi-turn dialogues, combine domain-specific instruments, and cling to complicated coverage constraints—capabilities that conventional analysis strategies wrestle to evaluate. Present benchmarks depend on small-scale, manually curated datasets with coarse metrics, failing to seize the dynamic interaction of insurance policies, person interactions, and real-world variability. This hole limits the flexibility to diagnose weaknesses or optimize brokers for deployment in high-stakes environments like healthcare or finance, the place reliability is non-negotiable.
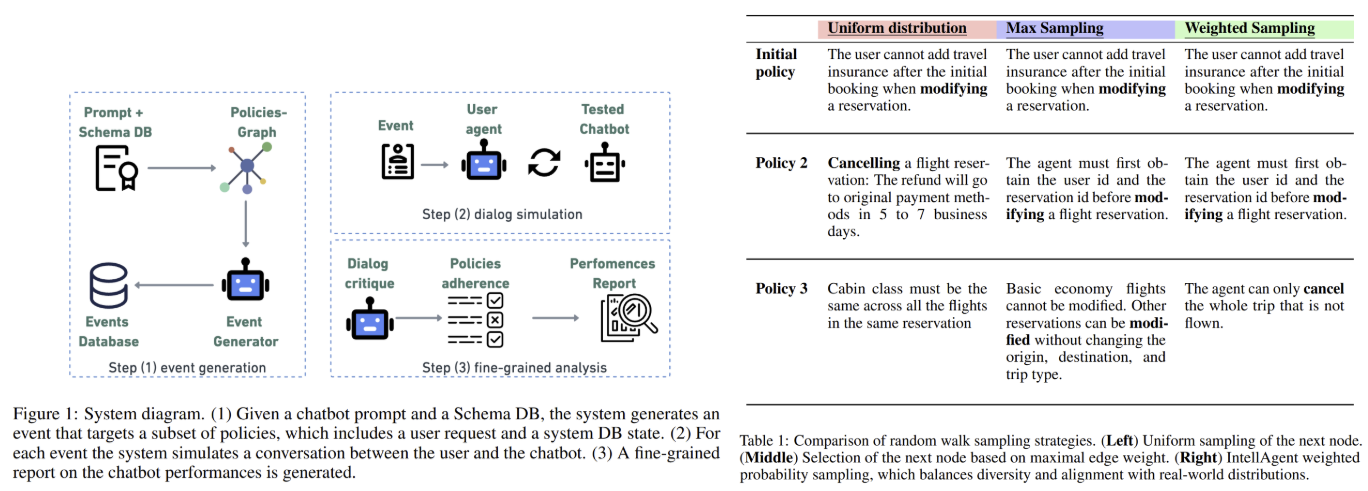
Present analysis frameworks, similar to τ-bench or ALMITA, give attention to slim domains like buyer assist and use static, restricted datasets. For instance, τ-bench evaluates airline and retail chatbots however contains solely 50–115 manually crafted samples per area. These benchmarks prioritize end-to-end success charges, overlooking granular particulars like coverage violations or dialogue coherence. Different instruments, similar to these assessing retrieval-augmented era (RAG) programs, lack assist for multi-turn interactions. The reliance on human curation restricts scalability and variety, leaving conversational AI evaluations incomplete and impractical for real-world calls for. To deal with these limitations, Plurai researchers have launched IntellAgent, an open-source, multi-agent framework designed to automate the creation of various, policy-driven situations. In contrast to prior strategies, IntellAgent combines graph-based coverage modeling, artificial occasion era, and interactive simulations to judge brokers holistically.
At its core, IntellAgent employs a coverage graph to mannequin the relationships and complexities of domain-specific guidelines. Nodes on this graph symbolize particular person insurance policies (e.g., “refunds have to be processed inside 5–7 days”), every assigned a complexity rating. Edges between nodes denote the chance of insurance policies co-occurring in a dialog. As an example, a coverage about modifying flight reservations may hyperlink to a different about refund timelines. The graph is constructed utilizing an LLM, which extracts insurance policies from system prompts, ranks their issue, and estimates co-occurrence possibilities. This construction allows IntellAgent to generate artificial occasions as proven in Determine 4—person requests paired with legitimate database states—by way of a weighted random stroll. Beginning with a uniformly sampled preliminary coverage, the system traverses the graph, accumulating insurance policies till the entire complexity reaches a predefined threshold. This method ensures occasions span a uniform distribution of complexities whereas sustaining lifelike coverage mixtures.
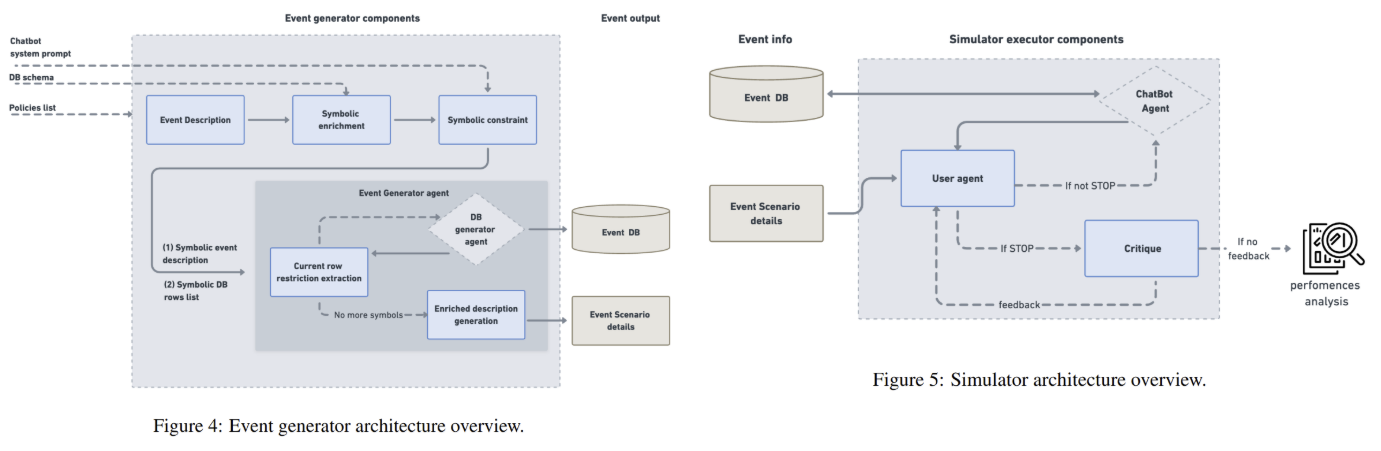
As soon as occasions are generated, IntellAgent simulates dialogues between a person agent and the chatbot underneath testa as proven in Determine 5. The person agent initiates requests primarily based on occasion particulars and displays the chatbot’s adherence to insurance policies. If the chatbot violates a rule or completes the duty, the interplay terminates. A critique part then analyzes the dialogue, figuring out which insurance policies have been examined and violated. For instance, in an airline situation, the critique may flag failures to confirm person id earlier than modifying a reservation. This step produces fine-grained diagnostics, revealing not simply general efficiency however particular weaknesses, similar to struggles with person consent insurance policies—a class neglected by τ-bench.
To validate IntellAgent, researchers in contrast its artificial benchmarks in opposition to τ-bench utilizing state-of-the-art LLMs like GPT-4o, Claude-3.5, and Gemini-1.5. Regardless of relying completely on automated information era, IntellAgent achieved Pearson correlations of 0.98 (airline) and 0.92 (retail) with τ-bench’s manually curated outcomes. Extra importantly, it uncovered nuanced insights: all fashions faltered on person consent insurance policies, and efficiency declined predictably as complexity elevated, although degradation patterns assorted between fashions. As an example, Gemini-1.5-pro outperformed GPT-4o-mini at decrease complexity ranges however converged with it at increased tiers. These findings spotlight IntellAgent’s capability to information mannequin choice primarily based on particular operational wants. The framework’s modular design permits seamless integration of latest domains, insurance policies, and instruments, supported by an open-source implementation constructed on the LangGraph library.
In conclusion, IntellAgent addresses a important bottleneck in conversational AI growth by changing static, restricted evaluations with dynamic, scalable diagnostics. Its coverage graph and automatic occasion era allow complete testing throughout various situations, whereas fine-grained critiques pinpoint actionable enhancements. By correlating carefully with current benchmarks and exposing beforehand undetected weaknesses, the framework bridges the hole between analysis and real-world deployment. Future enhancements, similar to incorporating actual person interactions to refine coverage graphs, might additional elevate its utility, solidifying IntellAgent as a foundational instrument for advancing dependable, policy-aware conversational brokers.
Take a look at the Paper and GitHub Web page. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 70k+ ML SubReddit.
Vineet Kumar is a consulting intern at MarktechPost. He’s at the moment pursuing his BS from the Indian Institute of Expertise(IIT), Kanpur. He’s a Machine Studying fanatic. He’s enthusiastic about analysis and the newest developments in Deep Studying, Laptop Imaginative and prescient, and associated fields.









{kind=link}