
The panorama of AI analysis is experiencing vital challenges as a result of immense computational necessities of huge pre-trained language and imaginative and prescient fashions. Coaching even comparatively modest fashions demand substantial assets; for example, Pythia-1B requires 64 GPUs for 3 days, whereas RoBERTa wants 1,000 GPUs for a single day. This computational barrier impacts tutorial laboratories, limiting their capability to conduct managed pre-training experiments. Furthermore, missing transparency concerning pre-training prices in academia creates extra obstacles, making it troublesome for researchers to plan experiments, suggest sensible grant budgets, and effectively allocate assets.
Earlier makes an attempt to deal with computational challenges in AI analysis embody Compute surveys that discover useful resource entry and environmental impacts however most centered narrowly on NLP communities. Subsequent, coaching optimization strategies rely on guide tuning with specialised data, whereas techniques like Deepspeed Autotune deal with batch measurement and Zero-based mannequin sharding optimizations. Some researchers have developed environment friendly pre-training recipes for fashions like BERT variants, reaching sooner coaching occasions on restricted GPUs. Furthermore, {Hardware} suggestion research have supplied detailed steering on tools choice however spotlight throughput metrics fairly than sensible coaching time concerns. These approaches nonetheless want to completely tackle the necessity for model-agnostic, replication-focused options that keep authentic structure integrity.
Researchers from Brown College have proposed a complete strategy to make clear pre-training capabilities in tutorial settings. Their methodology combines a survey of educational researchers’ computational assets with empirical measurements of mannequin replication occasions. A novel benchmark system is developed that evaluates pre-training period throughout completely different GPUs and identifies optimum settings for max coaching effectivity. By means of in depth experimentation involving 2,000 GPU hours, there are vital enhancements in useful resource utilization. The outcomes spotlight potential enhancements for tutorial pre-training, displaying that fashions like Pythia-1B will be replicated utilizing fewer GPU days than initially required.
The proposed technique makes use of a dual-category optimization technique: free-lunch strategies and memory-saving strategies. Free-lunch strategies signify optimizations with enhancements in throughput and potential reminiscence discount with out shedding efficiency or requiring person intervention. These embody mannequin compilation, utilizing off-the-shelf customized kernels as drop-in replacements for PyTorch modules, and using TF32 mode for matrix operations. However, Reminiscence-saving strategies cut back reminiscence consumption, introducing some efficiency trade-offs consisting of three key elements: activation checkpointing, mannequin sharding, and offloading. The system evaluates as much as 22 distinctive combos of memory-saving strategies whereas sustaining free-lunch optimizations as a continuing baseline.
The empirical outcomes present vital enhancements over preliminary analytical predictions, that are overly optimistic by an element of 6 occasions. Preliminary testing exhibits that 9 out of 20 model-GPU configurations should not possible, with Pythia-1B requiring 41 days on 4 A100 GPUs utilizing naive implementation. Nevertheless, after implementing the optimized configuration strategies, the analysis achieved a mean 4.3 occasions speedup in coaching time, decreasing Pythia-1B coaching to only 18 days on the identical {hardware} setup. Furthermore, the research reveals a shocking profit: memory-saving strategies, earlier related to velocity discount, generally improved coaching time by as much as 71%, particularly for GPUs with restricted reminiscence or bigger fashions.
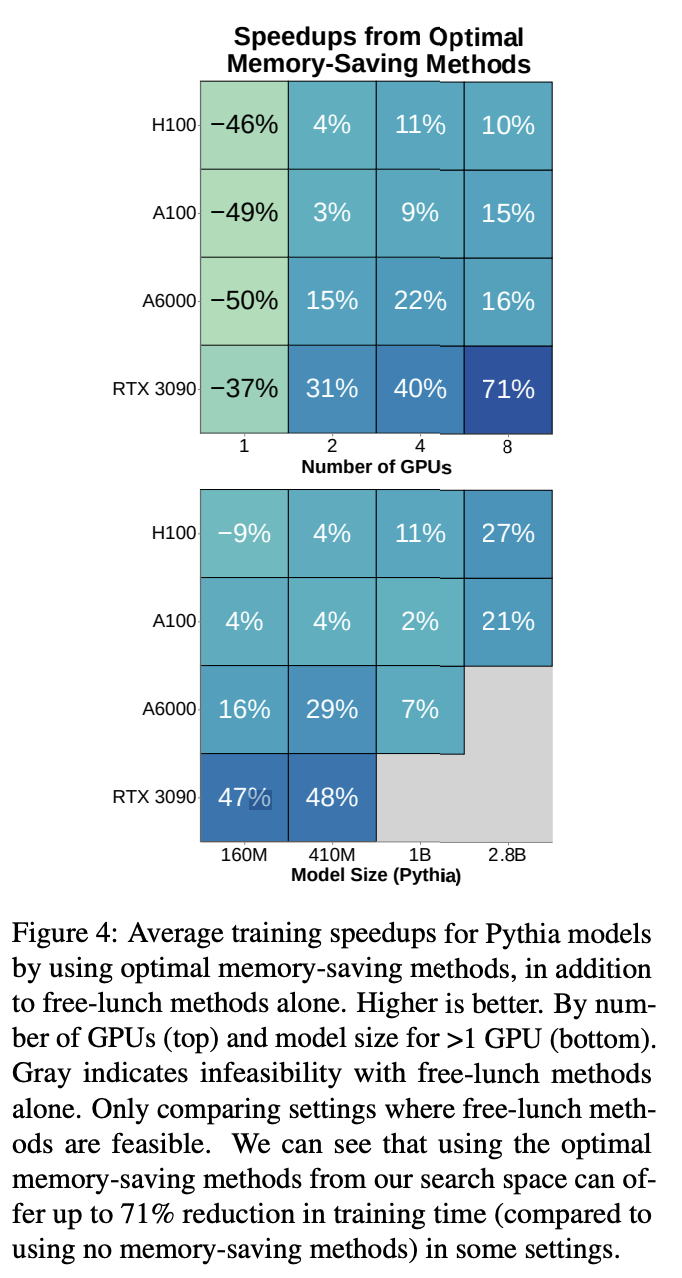
In conclusion, researchers from Brown College current a big step towards bridging the rising computational divide between business and academia in AI analysis. The research exhibits that tutorial establishments can practice billion-parameter fashions regardless of useful resource limitations. The developed codebase and benchmark system present sensible instruments for researchers to guage and optimize their {hardware} configurations earlier than making substantial investments. It permits tutorial teams to seek out optimum coaching settings particular to their accessible assets and run preliminary exams on cloud platforms. This work marks an vital milestone in empowering tutorial researchers to have interaction extra actively in large-scale AI mannequin growth.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t overlook to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. For those who like our work, you’ll love our e-newsletter.. Don’t Neglect to affix our 55k+ ML SubReddit.
[Sponsorship Opportunity with us] Promote Your Analysis/Product/Webinar with 1Million+ Month-to-month Readers and 500k+ Group Members

Sajjad Ansari is a ultimate 12 months undergraduate from IIT Kharagpur. As a Tech fanatic, he delves into the sensible purposes of AI with a deal with understanding the affect of AI applied sciences and their real-world implications. He goals to articulate complicated AI ideas in a transparent and accessible method.







{kind=link}