
Lengthy-context LLMs allow superior purposes corresponding to repository-level code evaluation, long-document question-answering, and many-shot in-context studying by supporting prolonged context home windows starting from 128K to 10M tokens. Nonetheless, these capabilities include computational effectivity and reminiscence utilization challenges throughout inference. Optimizations that leverage the Key-Worth (KV) cache have emerged to deal with these points, specializing in bettering cache reuse for shared contexts in multi-turn interactions. Methods like PagedAttention, RadixAttention, and CacheBlend intention to scale back reminiscence prices and optimize cache utilization however are sometimes evaluated solely in single-turn situations, overlooking real-world multi-turn purposes.
Efforts to enhance long-context inference deal with decreasing computational and reminiscence bottlenecks throughout pre-filling and decoding phases. Pre-filling optimizations, corresponding to sparse consideration, linear consideration, and immediate compression, cut back the complexity of dealing with massive context home windows. Decoding methods, together with static and dynamic KV compression, cache offloading, and speculative decoding, intention to handle reminiscence constraints successfully. Whereas these strategies improve effectivity, many depend on lossy compression strategies, which may compromise efficiency in multi-turn settings the place prefix caching is important. Present conversational benchmarks prioritize single-turn evaluations, leaving a spot in assessing options for shared contexts in real-world situations.
Researchers from Microsoft and the College of Surrey launched SCBench, a benchmark designed to judge long-context strategies in LLMs by means of a KV cache-centric method. SCBench assesses 4 phases of KV cache: technology, compression, retrieval, and loading throughout 12 duties and two shared context modes (multi-turn and multi-request). The benchmark analyzes strategies like sparse consideration, compression, and retrieval on fashions corresponding to Llama-3 and GLM-4. Outcomes spotlight that sub-O(n) reminiscence strategies battle in multi-turn situations, whereas O(n) reminiscence approaches carry out robustly. SCBench offers insights into sparsity results, activity complexity, and challenges like distribution shifts in long-generation situations.
The KV-cache-centric framework categorizes long-context strategies in LLMs into 4 phases: technology, compression, retrieval, and loading. Technology consists of strategies like sparse consideration and immediate compression, whereas compression includes strategies like KV cache dropping and quantization. Retrieval focuses on fetching related KV cache blocks to optimize efficiency, and loading includes dynamically transferring KV information for computation. The SCBench benchmark evaluates these strategies throughout 12 duties, together with string and semantic retrieval, multi-tasking, and world processing. It analyzes efficiency metrics, corresponding to accuracy and effectivity, whereas providing insights into algorithm innovation, together with Tri-shape sparse consideration, which improves multi-request situations.
The researchers evaluated six open-source long-context LLMs, together with Llama-3.1, Qwen2.5, GLM-4, Codestal-Mamba, and Jamba, representing varied architectures corresponding to Transformer, SSM, and SSM-Consideration hybrids. Experiments used BFloat16 precision on NVIDIA A100 GPUs with frameworks like HuggingFace, vLLM, and FlashAttention-2. Eight long-context options have been examined, together with sparse consideration, KV cache administration, and immediate compression. Outcomes confirmed that MInference outperformed in retrieval duties, whereas A-shape and Tri-shape excelled in multi-turn duties. KV compression strategies and immediate compression yielded blended outcomes, typically underperforming in retrieval duties. SSM-attention hybrids struggled in multi-turn interactions, and gated linear fashions confirmed poor efficiency general.
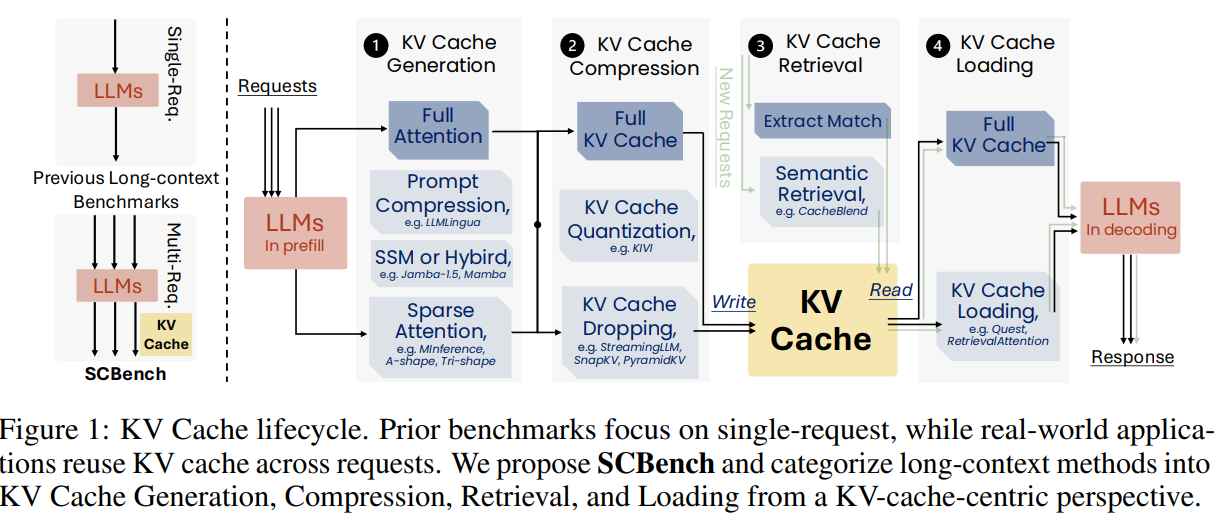
In conclusion, the examine highlights a crucial hole in evaluating long-context strategies, which historically deal with single-turn interactions, neglecting multi-turn, shared-context situations prevalent in real-world LLM purposes. The SCBench benchmark is launched to deal with this, assessing long-context strategies from a KV cache lifecycle perspective: technology, compression, retrieval, and loading. It consists of 12 duties throughout two shared-context modes and 4 key capabilities: string retrieval, semantic retrieval, world info processing, and multitasking. Evaluating eight long-context strategies and 6 state-of-the-art LLMs reveals that sub-O(n) strategies battle in multi-turn settings. In distinction, O(n) approaches excel, providing worthwhile insights for bettering long-context LLMs and architectures.
Try the Paper and Dataset. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to hitch our 60k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is enthusiastic about making use of know-how and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.









{kind=link}