
The analysis of LLMs in medical duties has historically relied on multiple-choice query benchmarks. Nonetheless, these benchmarks are restricted in scope, typically yielding saturated outcomes with repeated excessive efficiency from LLMs, and don’t precisely mirror real-world medical eventualities. Medical reasoning, the cognitive course of physicians use to investigate and synthesize medical information for analysis and remedy, is a extra significant benchmark for assessing mannequin efficiency. Latest LLMs have demonstrated the potential to outperform clinicians in routine and complicated diagnostic duties, surpassing earlier AI-based diagnostic instruments that utilized regression fashions, Bayesian approaches, and rule-based methods.
Advances in LLMs, together with basis fashions, have considerably outperformed medical professionals in diagnostic benchmarks, with methods corresponding to CoT prompting additional enhancing their reasoning skills. OpenAI’s o1-preview mannequin, launched in September 2024, integrates a local CoT mechanism, enabling extra deliberate reasoning throughout advanced problem-solving duties. This mannequin has outperformed GPT-4 in addressing intricate challenges like informatics and drugs. Regardless of these developments, multiple-choice benchmarks fail to seize the complexity of medical decision-making, as they typically allow fashions to leverage semantic patterns slightly than real reasoning. Actual-world medical observe calls for dynamic, multi-step reasoning, the place fashions should repeatedly course of and combine various information sources, refine differential diagnoses, and make vital choices underneath uncertainty.
Researchers from main establishments, together with Beth Israel Deaconess Medical Middle, Stanford College, and Harvard Medical Faculty, carried out a research to judge OpenAI’s o1-preview mannequin, designed to boost reasoning by means of chain-of-thought processes. The mannequin was examined on 5 duties: differential analysis era, reasoning rationalization, triage analysis, probabilistic reasoning, and administration reasoning. Skilled physicians assessed the mannequin’s outputs utilizing validated metrics and in contrast them to prior LLMs and human benchmarks. Outcomes confirmed important enhancements in diagnostic and administration reasoning however no developments in probabilistic reasoning or triage. The research underscores the necessity for strong benchmarks and real-world trials to judge LLM capabilities in medical settings.
The research evaluated OpenAI’s o1-preview mannequin utilizing various medical diagnostic circumstances, together with NEJM Clinicopathologic Convention (CPC) circumstances, NEJM Healer circumstances, Gray Issues administration circumstances, landmark diagnostic circumstances, and probabilistic reasoning duties. Outcomes centered on differential analysis high quality, testing plans, medical reasoning documentation, and figuring out vital diagnoses. Physicians assessed scores utilizing validated metrics like Bond Scores, R-IDEA, and normalized rubrics. The mannequin’s efficiency was in comparison with historic GPT-4 controls, human benchmarks, and augmented assets. Statistical analyses, together with McNemar’s take a look at and mixed-effects fashions, have been carried out in R. Outcomes highlighted o1-preview’s strengths in reasoning however recognized areas like probabilistic reasoning needing enchancment.
The research evaluated o1-preview’s diagnostic capabilities utilizing New England Journal of Drugs (NEJM) circumstances and benchmarked it in opposition to GPT-4 and physicians. o1-preview appropriately included the analysis in 78.3% of NEJM circumstances, outperforming GPT-4 (88.6% vs. 72.9%). It achieved excessive test-selection accuracy (87.5%) and scored completely on medical reasoning (R-IDEA) for 78/80 NEJM Healer circumstances, surpassing GPT-4 and physicians. In administration vignettes, o1-preview outperformed GPT-4 and physicians by over 40%. It achieved a median rating of 97% for landmark diagnostic circumstances, akin to GPT-4 however larger than physicians. Probabilistic reasoning was carried out equally to GPT -4, with higher accuracy in coronary stress exams.
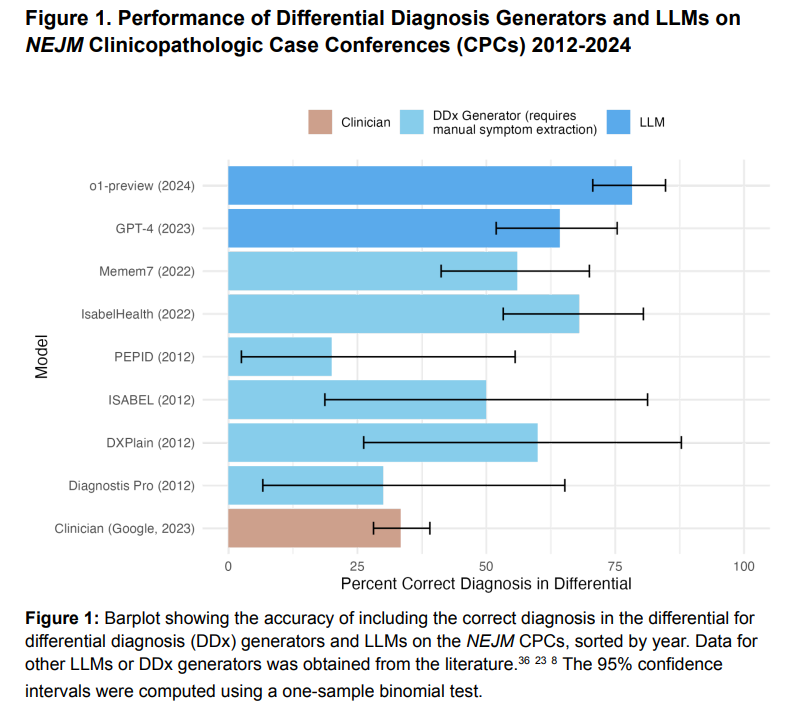
In conclusion, The o1-preview mannequin demonstrated superior efficiency in medical reasoning throughout 5 experiments, surpassing GPT-4 and human baselines in duties like differential analysis, diagnostic reasoning, and administration choices. Nonetheless, it confirmed no important enchancment over GPT-4 in probabilistic reasoning or vital analysis identification. These spotlight the potential of LLMs in medical resolution help, although real-world trials are essential to validate their integration into affected person care. Present benchmarks, like NEJM CPCs, are nearing saturation, prompting the necessity for extra reasonable, difficult evaluations. Limitations embrace verbosity, lack of human-computer interplay research, and a deal with inside drugs, underscoring the necessity for broader assessments.
Try the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t overlook to comply with us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Overlook to affix our 60k+ ML SubReddit.
Sana Hassan, a consulting intern at Marktechpost and dual-degree pupil at IIT Madras, is captivated with making use of expertise and AI to deal with real-world challenges. With a eager curiosity in fixing sensible issues, he brings a contemporary perspective to the intersection of AI and real-life options.









{kind=link}